


尊敬的支持团队:
我们在定制板 上使用 PRU-ICSS-HSR-PRP-DAN_01.00.02.00数据包软件。 我们发现、当我们使用 PRP 网络设置时、我们会不时收到大量 CPU 负载。 当使用两个端口时、更有可能出现此问题。 我们注意对硬件跟踪分析器(PC 跟踪)进行调试、并发现该程序主要在 ICSS_EMacOSRxTaskFnc ( ICSS_EmacPollPkt, ICSS_EmacRxPktInfo2, RedRxPktGet...)中循环。 由于网络流量很小、设备上没有发送任何特别的数据、因此我们变得很可疑、与之前的 Rx 操作相比、我们没有进行任何数据包泛洪(通过 Wireshark 跟踪)、但 CPU 在 Rx 时被占用。
我们进一步调查并发现在 RedRxPktGet 中,程序有时读取 长度为2B 的数据包, 而 qDesc->wr_ptr 有时在队列区域之外有一个值(qwr->Desc_ptr == 4)。 我们认为这会导致连续读取、queue_rd_ptr 尝试捕获 队列缓冲区之外的 queue_wr_ptr。 经过一段时间的时间、纠正了 queue_wr_ptr 并返回到队列指针区域、然后在 queue_wr_ptr 中对 queue_rd_ptr 进行了均衡化。 这种情况会产生大量错误和重复的数据包、丢包、重新传输以及最烦人的100% CPU 负载、这会影响我们的时间关键型应用。
我们发现、在 PRP 上的最大 MTU (1514B)上、当数据包的尾部被添加到数据包中时、数据包的大小为1520、由 NIMUReceivePacket 丢弃。
我们知道1.00.02版本不再受支持、因此我们开始在 IDKam437x 开发套件(没有我们的应用程序代码的原始数据包)上测试 PRU-ICSS-HSR-PRP-DAN_01.00.05.01、以调查新版本中是否存在相同的问题(检查移植到新版本是否会有任何进展)。 为了进行调试、我们添加了 NDK 回显服务器。 版本1.0.5.1在某种程度上更加稳定、但我们发现错误的指针和数据包长度也存在同样的问题。
为了进行测试、我们将这些代码行放入代码中:
rd_packet_length = (0x1ffc0000 & rd_buf_desc) >> 18;
size = (rd_packet_length >> 2);
if((rd_packet_length & 0x00000003) != 0)
{
size = size + 1;
}
/** our traceing structure*/
uint32_t structIndex = 0;
structIndex = red_debug_ind_incr();
red_debug[structIndex].queueNumber = queueNumber;
red_debug[structIndex].queue_rd_ptr = queue_rd_ptr;
red_debug[structIndex].queue_wr_ptr = queue_wr_ptr;
red_debug[structIndex].rd_packet_length = rd_packet_length;
/*Compute number of buffer desc required & update rd_ptr in queue */
update_rd_ptr = ((rd_packet_length >> 5) * 4) + queue_rd_ptr;
if((rd_packet_length & 0x0000001f) !=
0) /* checks multiple of 32 else need to increment by 4 */
{
update_rd_ptr += 4;
}
/*Check for wrap around */
if(update_rd_ptr >= rxQueue->queue_size)
{
update_rd_ptr = update_rd_ptr - (rxQueue->queue_size -
rxQueue->buffer_desc_offset);
}
red_debug[structIndex].queue_update_rd_ptr = update_rd_ptr;
if (rd_packet_length < 60) {
__asm__("BKPT");
}
if(queue_wr_ptr < rxQueue->buffer_desc_offset){
__asm__("BKPT");
}
if(queue_rd_ptr < rxQueue->buffer_desc_offset){
__asm__("BKPT");
}
一段时间后、asm 断点被命中、 以下 是解释 wr_ptr 和 len 发生情况的屏幕截图:
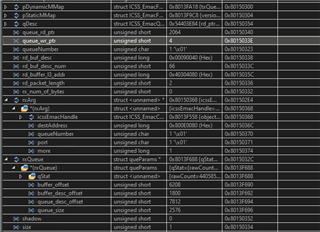
这是当前 和过去 RedRxPktGet 调用中指针的流程(请注意,在288个队列中,queue_exit_wP_ptr 未更新 jet,并且是无效的数字-如果需要设置 rxArg->More = 1,则在函数检查时存储此值;):
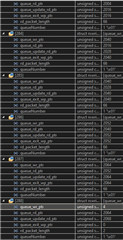
重复此测试并检查记录 的指针后、我们发现当"wr"和"rd"指针相等时、问题更有可能发生。 我们还观察到、当 Rr 和 rd 指针相等时、有时会发生这样的情况:两个指针在队列位置被 PRU 调整得更低、就像试图阻止缓冲区换行一样。 是这样吗?
在较重的交通中更有可能出现此问题。
您是否观察到这种行为?
我们还怀疑回波数据包(TX)在 RX 问题后尾是否断裂(我们不确定、但我们认为一旦在 PRP 数据包的尾部放置了一些"回波"有效载荷)。
我们还找到了此主题 :https://e2e.ti.com/support/processors-group/processors/f/processors-forum/1017202/amic110-ethernet-ip-trouble/3765093?tisearch=e2e-sitesearch&keymatch=wr_ptr#3765093、它可能与我们观察到的内容类似。 您能解释一下这条线程的结论是什么吗?
你有什么想法吗? 您能回答我们的调查结果并发表意见吗?
此致、Mare
