请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
部件号:TM4C129XNCZAD 您好,
我们最近遇到了与使用硬件CRC相关的意外问题。
我们的代码非常简单,经过测试,没有任何问题....
// Write the control register with the configuration
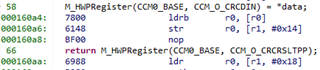
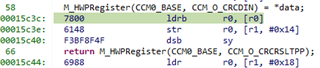
M_HWPRegister(CCM0_BASE, CCM_O_CRCCTRL) = (CRC_CFG_INIT_1 |
CRC_CFG_SIZE_8BIT |
CRC_CFG_TYPE_P1021);
// Feed the CRC module with data
while (length-- != 0u)
{
M_HWPRegister(CCM0_BASE, CCM_O_CRCDIN) = *bytes++;
}
// Return post processed value
return M_HWPRegister(CCM0_BASE, CCM_O_CRCRSLTPP);
....直到我们应用-O2优化。
应用-O2优化后,我们会检查汇编代码是否正确,但在运行代码时和在汇编中逐步进行时,计算出的CRC是不同的。
经过进一步调查后,在逐步执行时CRC是正确的,但在运行代码时,返回的CRC是阵列长度-1第一个字节中的一个,在本例中,当停止处理器时,CCM0模块寄存器中包含正确的CRC, 与函数返回的内容相反。
引用数据表中的内容:
"CRC在一个时钟中组合计算。"
"由于CRC计算是单个周期,一旦数据写入CRC数据输入(CRCDIN)寄存器,CRC/CSUM的结果将在CRC种子/上下文(CRCSEED)寄存器中更新,偏移0x410。"
这是否不正确? 读取 CRC后处理结果(CRCRSLTPP)寄存器时是否存在未记录的计时? CRC计算如何能进行一个周期而不是XOR或位反转?
我们在最后写入的字节和后处理结果的读取之间添加了一个NOP指令,它似乎起作用。 但是,由于我们在一家医疗设备公司工作,这是一个不可接受的修补程序,但没有提供任何其他信息来证明其合理性。
此致,
Matthieu Tardivon