请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TM4C1294NCPDT 早上好!
在每个文件中:
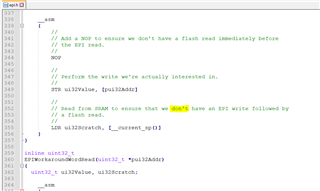
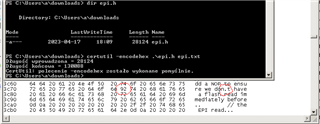
tivaware_c_series_2_1_4_178/driverlib/epi.h
TivaWare_C_Series-2.2.0.295/driverlib/epi.h
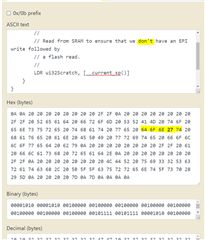
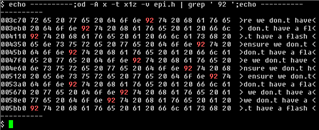
在12个地方使用奇怪(非纯 ASCII) 0x92撇号代替纯 ASCII 0x37代码。
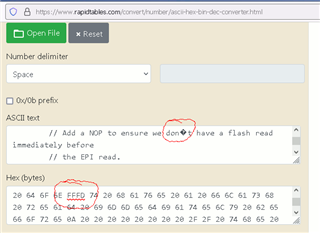
我使用的是使用 UTF-8的波兰语字母,在解码"epi.h"文件时,我在 Python 中得到了错误3 :
UnicodeDecodeError:'UTF-8编码解码器无法解码位置15481:无效的起始字节0x92
使用单引号(ASCII 十六进制代码0x37)时、此错误消失。
TivaWare 中的几乎所有*。c/*。h 文件均使用普通的0x37撇号、仅使用"epi.h"(以及"tivaware_c_serial_2_1_4_178/examples/boards/dk-tm4c129x/ble_central/ble_central.c")使用0x92代码表示撇号字符。

祝你一切顺利。
Piotr Kasprzyk