Other Parts Discussed in Thread: AM2431, LP-AM243
请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM2431 主题中讨论的其他器件: LP-AM243
您好!所有 TI 专家!
我目前的产品使用 AM2431作为主芯片、我现在使用的 SDK 是 mcu_plus_sdk_am243x_09_01_00_41。 我参考了 enet_layer2_cpsw 示例程序、并针对我们的应用程序对其进行了修改。
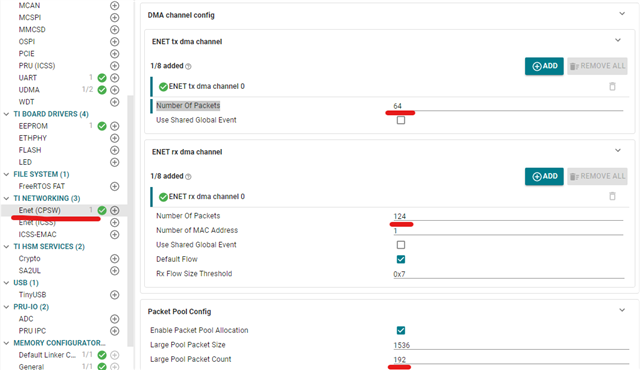
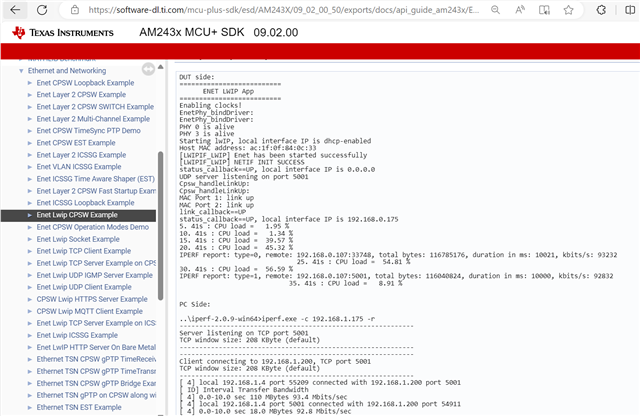
最近、我遇到了一个问题、即系统正常运行、只有几个以太网数据包、但当存在大量数据包时、会出现错误。 我发现该问题与以太网(CPSW)-> ENET RX DMA 通道>数据包池配置中的配置设置有关。 大型池数据包计数的最大设置为192、但我的系统在8ms 内发送807个数据包、每个数据包为1461字节。 传输后、有大约20ms 的空闲周期、允许 MCU 处理数据包。 使用 Wireshark 的观察结果显示、数据速率约为125Mbps、鉴于 AM2431处理千兆位以太网的能力、它从理论上应该管理此工作负载。 不过、似乎数据包的数量太大、没有足够的 DMA 空间来处理所有这些数据包。 我正在寻找有关如何解决此问题的任何建议。 谢谢!
此致!
拉里