请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:BEAGLEBN
您好!
我在 BeagleBone 中使用 PRU。 PRU 软件用 clpru 2.2.1编写。
我无法达到项目的计时目标。
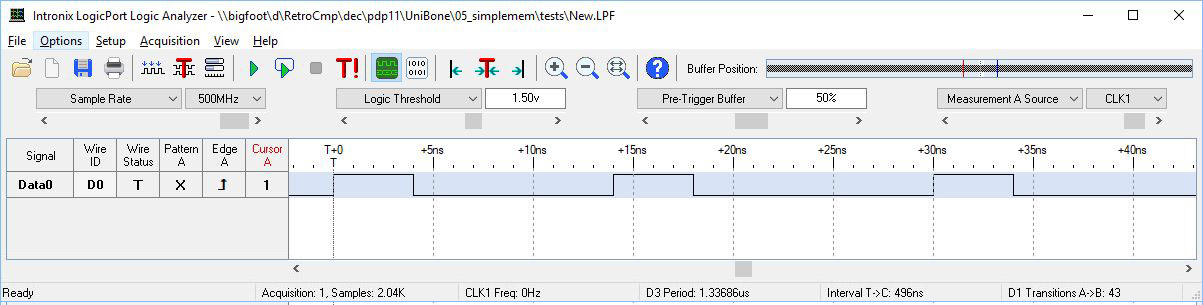
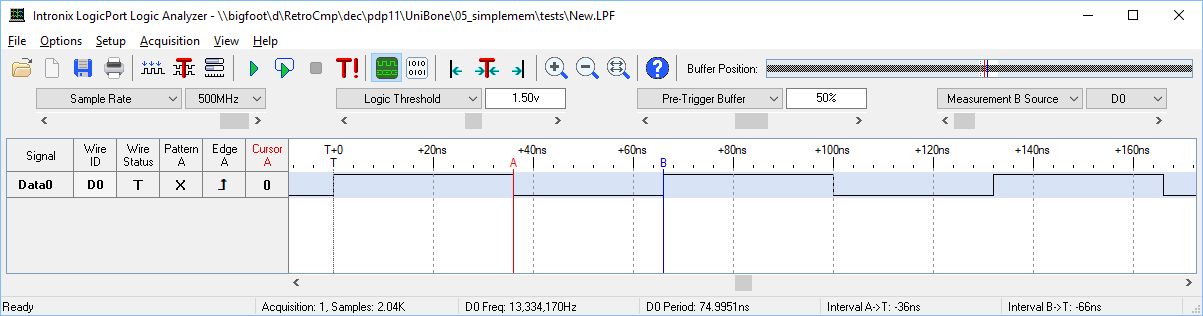
调试会导致 GPIO 上的简单回写操作需要40ns 才能完成、而不是像预期的10ns。
测试设置:我切换 R30输出引脚并等待 R31上再次出现电压电平。
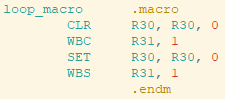
代码:
while (1){
_R30 |=(1 << 12);//设置 PRU1.12
while (!(_R31和0x80));//等待直到 DATAIN7上的回读
_R30 &&~(1 << 12);//清除 PRU1.12
while (__R31和0x80);//等待 DATAIN7的回读
}
逻辑分析仪显示了单个
_R30 |=(1 << 12);//设置 PRU1.12
while (!(_R31和0x80));//等待
需要40纳秒。
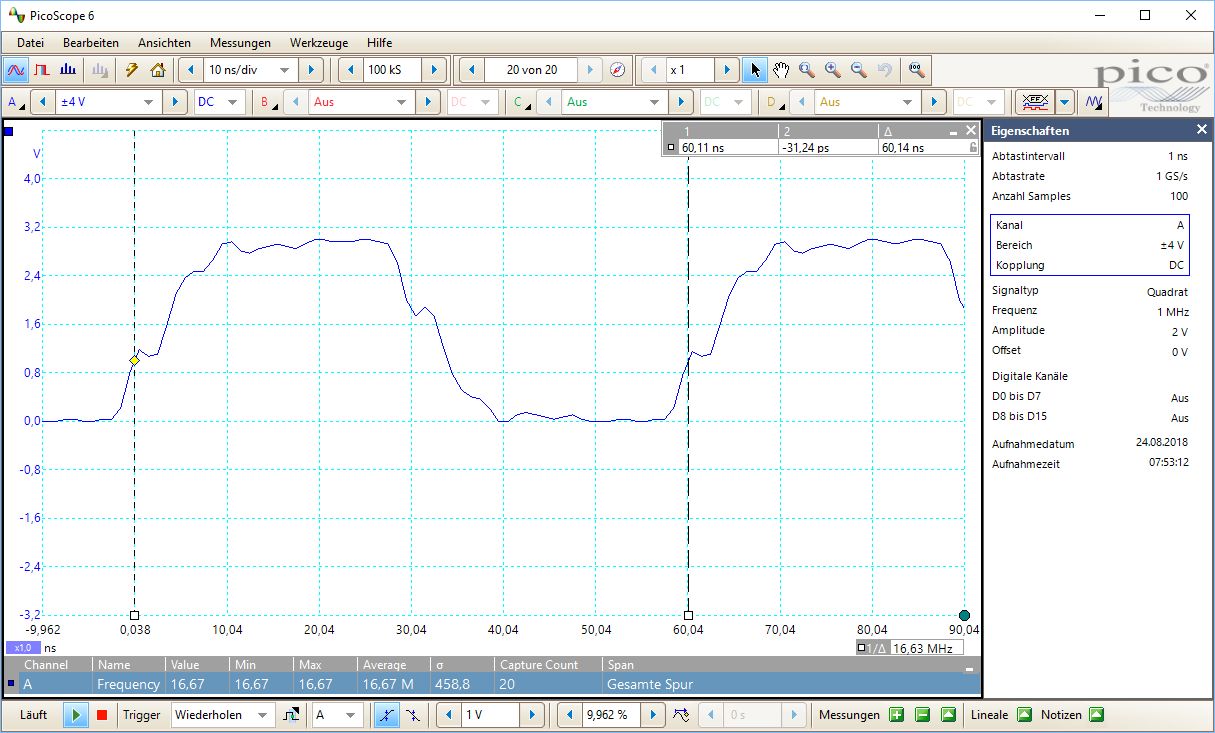
我 可以使用在66MHz 频率下生成良好的方波
while (1){
_R30 |=(1 << 12);// 5ns
_R30 &&~(1 << 12);// 5ns
}
因此、"while (!(_R31和0x80)"部件需要35ns。
http://processors.wiki.ti.com/index.php/AM335x_PRU_Read_Latencies 显示:EGPIO 读取为1个周期= 5ns。
BeagleBone 本身显然不包含低通。
什么会导致 EGPIO R31读取延迟7个周期?
感谢您的关怀、
Joerg Hoppe、 PEAK System Technik GmbH