

此常见问题解答讨论了可编程毫米波传感器上实现的应用的存储器架构和分配。
可编程毫米波传感器包括一个 ARM 内核(MSS)和以下一个或两个处理引擎: 硬件加速器(HWA)和 DSP (DSS)。
对于第1代毫米波传感器、DSP 是 C647x;对于第2代器件、DSP 是 C66系列的一部分。
以下文档包含有关 C647x 和 C66x 存储器子系统的详细信息:
对于 C647x:
《C64x+超级模块用户指南》
https://www.ti.com/lit/ug/spru871k/spru871k.pdf
适用于 C66
TMS320C66x DSP CorePac
https://www.ti.com/lit/ug/sprugw0c/sprugw0c.pdf
毫米波传感器通常包含以下存储器:
- L1P、L1D、L2 - DSS 存储器
- DSS_L3 -共享存储器
- 硬件加速器输入/输出存储器
- MSS_TCMA
- MSS_TCMB - ARM 数据存储器
在毫米波应用中、雷达处理通常在 HWA 或 DSS 上实现。
使用 HWA 为处理分配存储器
为了使用 HWA 处理数据、必须使用专用的输入/输出缓冲器。 没有其他选择。
- 预处理输入数据通过 EDMA 从另一个存储器(如 L3)传输到 HWA 输入缓冲器
- 后处理使用 EDMA 将结果数据从 HWA 输出缓冲器传输到另一个存储器、例如 L3
为了优化处理、输入数据被组织在乒乓缓冲器中。 优化的原因是、当 EDMA 传输 PONG 数据时、会对 ping 缓冲器进行处理。 因此、EDMA 数据传输不会产生额外的延迟。 当然、此优化需要2个存储器缓冲器。
多普勒 FFT 的毫米波 SDK 演示文档中提供了这种处理类型的一个很好的示例。 参见 DopplerProcHWA
多普勒 DPU
使用 DSP 为处理分配内存
使用 DSP 处理数据时、首先需要对周期最密集的算法进行高度优化的实施。 为了获得最佳性能、需要使用定点算法。 如果需要更高精度的浮点格式、则可能需要使用浮点格式。 毫米波传感器中提供的 DSP 支持定点和浮点数据格式。 为了使这些实现提供最佳性能、它们必须从最快的程序和数据存储器:L1P 和 L1D 运行。
由于存储器 L1P 和 L1D 均可配置为器件存储器和器件高速缓存、因此应用开发人员可以选择
- 将部分 L1P 和 L1D 存储器用作高速缓存、部分用作存储器。
- 将所有 L1P 和 L1D 用作高速缓存
当 L1D 的一部分用作存储器时、应用程序必须在此存储器中分配输入和输出缓冲器以用于周期最密集的算法。 每个处理阶段的缓冲区都将重叠。
以下是毫米波 SDK 2.1演示的一个示例:
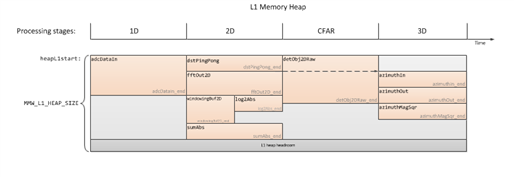
数据将使用 EDMA 传输到 L1D 缓冲器或从 L1D 缓冲器传输。 通常、输出结果会传输到 L3存储器。
