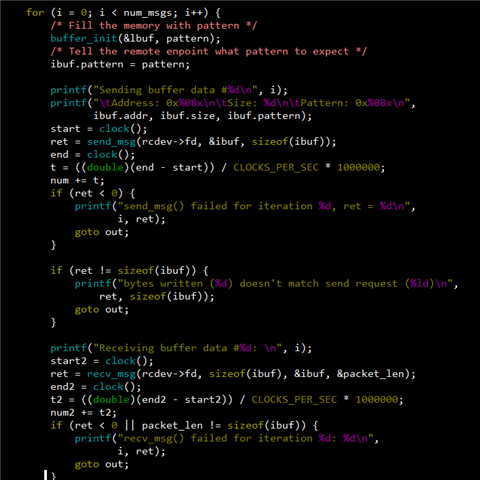
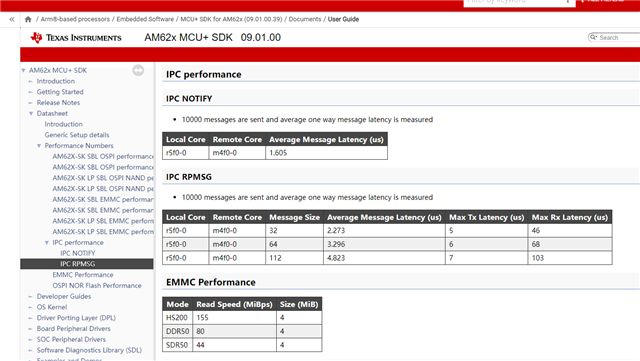
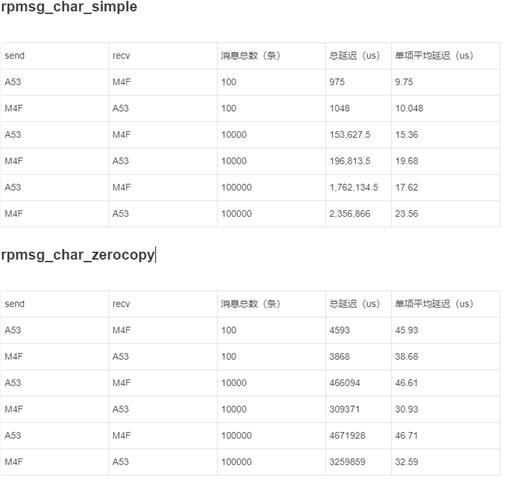
我想要知道这两个核间通信示例,哪一个传输数据的效率更快一些,我的测试结果如下所示,rpmsg_char_simple的结果与官方文档给出的结果类似。
rpmsg_char_zerocopy的方式比速度上要比rpmsg_char_simple慢,这个结论是否正确?
为什么rpmsg_char_zerocopy的方式会慢一点
Original question:
我想要知道这两个核间通信示例,哪一个传输数据的效率更快一些,我的测试结果如下所示,rpmsg_char_simple的结果与官方文档给出的结果类似。
rpmsg_char_zerocopy的方式比速度上要比rpmsg_char_simple慢,这个结论是否正确?
为什么rpmsg_char_zerocopy的方式会慢一点