1.关于EDMA转置读连续写和连续读转置写的传输速度问题,我不太理解以下这个表格针对不同的传输方式列出的传输周期数,我认为转置读连续写和连续读转置写的速度应该一样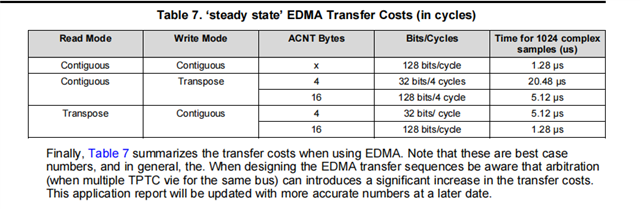
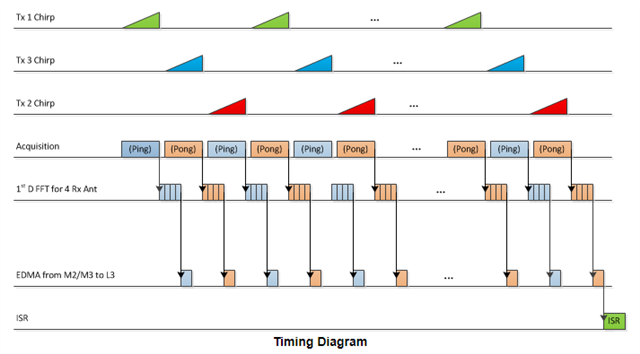
2.对于以下这个传输例子,在对TI的例程中EDMA的寄存器参数配置中发现了ADC_Buffer往HWA搬移数据的一个参数集,基于PING-PONG机制的理解,我不太清楚为什么EDMA要将ADC_Buffer中的数据,在HWA的MEM_0和MEM_1都放一次,我的正常理解应该是ADC_Buffer的PING放在HWA的MEM_0,PONG放在HWA的MEM_1,如此这样交替着来。
R TPCC0_PARAMSET_[9]_OPT 0x80C07004
R TPCC0_PARAMSET_[9]_SRC 0x21000000 //ADC_Buffer
R TPCC0_PARAMSET_[9]_A_B_CNT 0x00040400 //BCNT=4(一个B行有4个A块,一共256*4个样本),ACNT=1024-Byte(一个A块,一共256个样本)
R TPCC0_PARAMSET_[9]_DST 0x21030000 //HWA MEM0
R TPCC0_PARAMSET_[9]_SRC_DST_BIDX 0x04000400 //DSTBINDX=1024-Byte(目的不同B行之间偏移地址为1024-Byte/256个样本),SRCBINDX=1024-Byte(源不同B行之间偏移地址为1024-Byte/256个样本)
R TPCC0_PARAMSET_[9]_LINK_BCNTRLD 0x00004800 //
R TPCC0_PARAMSET_[9]_SRC_DST_CIDX 0x40000000 //DSTCINDX=16384-Byte(目的不同C帧之间偏移地址为16384-Byte/4096个样本),SRCCINDX=0
R TPCC0_PARAMSET_[9]_CCNT 0x00000002 //CCNT=2