

作者:Fredy Zhang;Kangjia Dong
深度学习是机器学习的一个子集,常用于自然语言处理,计算机视觉等领域,与众不同之处在于,DL(Deep Learning )算法可以自动从图像、视频或文本等数据中学习数据特征。DL可以直接从数据中学习,这比较类似于人脑的运行方式,获得更多数据后,准确度也会越来越高。TIDL(TI Deep Learning Library) 是TI平台基于深度学习算法的软件生态系统,可以将一些常见的深度学习算法模型快速的部署到TI嵌入式平台。 TDA4拥有TI最新一代的深度学习加速模块C7x DSP与MMA矩阵乘法加速器,可以运行TIDL进行卷积等基本计算,从而快速地进行前向推理,得到计算结果。 当深度学习遇上TDA4,你的模型部署流程将变得简单,你的模型将高效地运行在TDA4上。
TI 最新一代的汽车处理器TDA4VM集成了高性能计算单元C7x DSP(Digital Signal Processor)和Deep-learning Matrix Multiply Accelerator(MMA),可以高效地进行卷积计算、矩阵变换等一些基本地深度学习算子。TIDL 是TI的针对于嵌入式平台部署深度学习不方便,计算效率低下而设计的一个软件生态系统,用于加速 TI 嵌入式设备上的深度神经网络Deep Neural Networks (DNN)计算加速。 上一代产品 TDA2/3 系列处理器,集成了计算单元 DSP(Digital Signal Processor)和 EVE(Embedded Vision/Vector Engine),用于加速计算深度学习神经网络。相比于上一代TDA2/TDA3系列处理器,最新一代的TDA4处理器在算例上得到了大幅提高的同时,在软件方面提供了更好地支持,同时提供了更多的深度学习模型的部署示例,方便开发人员快速开发迭代产品,极大地缩短的产品开发周期。
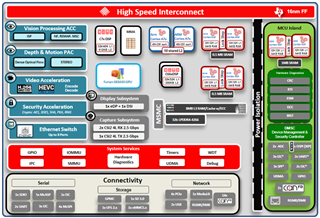
图1. TIDL SW Framework
基于深度神经网络 (DNN) 的机器学习算法用于许多行业,例如机器人、工业和汽车。越来越多的基于 DNN 的机器学习算法被应用于 ADAS 产品中,如车道线检测,交通信号灯识别,行人识别等ADAS基础功能均采用DNN算法实现。这些DNN神经网络算法通常需要大量的计算,而TI TDA4系列处理器中的C7x和MMA可以将一些DNN中的算子进行加速计算,以实现快速推理得到识别结果。RTOS SDK 中集成了众多的Demo展示TIDL在TDA4处理器上对实时的语义分割和 SSD 目标检测的能力。如下图2:AVP的demo展示了使用TIDL对泊车点、车辆的检测。

图2. TIDL SW Framework
TIDL当前支持的训练框架有Tensorflow、Pytorch、Caffe等,用户可以根据需要选择合适的训练框架进行模型训练。TIDL可以将PC端训练好的模型导入编译生成TIDL可以识别的模型格式,同时在导入编译过程中进行层级合并以及量化等操作,方便导入编译后的模型高效的运行在具有高性能定点数据感知能力TDA4硬件加速器上。 TIDL提供了一些的工具,如模型导入工具,模型可视化工具等,非常便捷地可以对训练好地模型进行导入。
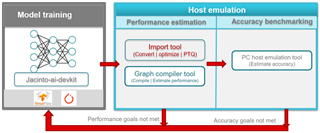
图3. TIDL Tools
TIDL Runtime 是运行在TDA4端的实时推理单元,同时提供了TIDL的运行环境,对于input tensor,TIDL TIOVX Node 调用TIDL 的深度学习加速库进行感知,并将结果进行输出。
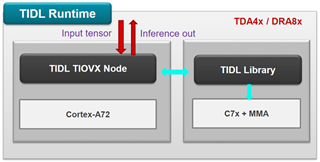
图4. TIDL Runtime
如图5所示,是TIDL的软件框架。在TIDL上,深度学习网络应用开发主要分为三个大的步骤(以TI Jacinto7TM TDA4VM处理器为例):
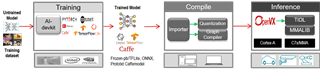
- 基于Tensorflow、Pytorch、Caffe 等训练框架,训练模型:选择一个训练框架,然后定义模型,最后使用相应的数据集训练出满足需求的模型。
- 基于TI Jacinto7TM TDA4VM处理器导入模型: 训练好的模型,需要使用TIDL Importer工具导入成可在TIDL上运行的模型。导入的主要目的是对输入的模型进行量化、优化并保存为TIDL能够识别的网络模型和网络参数文件。
- 基于TI Jacinto7TM SDK 验证模型,并在应用里面部署模型:
- PC 上验证并部署
- 在PC上使用TIDL推理引擎进行模型测试。
- 在PC上使用OpenVX框架开发程序,在应用上进行验证。
- EVM上验证并部署
- 在EVM上使用TIDL推理引擎进行模型测试。
- 在EVM上使用OpenVX框架开发程序,在应用上进行验证
- PC 上验证并部署
当深度学习遇上TDA4,模型部署变得简单的同时,模型也可以更加高效地运行。让我们开启TDA4的探索之旅,你的AI旅程将变得轻松愉快。