

Other Parts Discussed in Thread: TMS570LC4357
器件型号: TMS570LC4357
团队、
您能为以下问题提供帮助吗?
提前感谢、
Anthony
TMS570LC4357 连接到 NVRAM、EMIF 作为具有 16 位字宽的异步存储器。
关于周转期:
-在什么条件下,转换是插入的?
仅当在读取和写入/写入和读取之间切换、或者同时在两个读取/两个写入访问之间切换时?
一个 32 位存储器访问(这样会产生两个 16 位 EMIF 访问)与两个 16 位存储器访问一个接一个地放在这两者之间是否存在区别?
周转期是在哪里插入的?
在TRM SPNU563 第 814 页上、读数就像在 EMIF 访问之前插入一样。
但是、第 845 页的图 21-32 显示了访问后的情况。
-也不清楚哪些寄存器值会导致哪个设置、选通、保持和周转时间。
在 ‘mSPNU563 第 812 页上、每种情况下都使用“内部一个周期“一词、因此、我假设寄存器值 0 会导致一个 EMIF 周期的设置时间。
然而,第 812 页和第 845 页的信息和图表部分地与这一理论相矛盾。
在这种情况下、我尤其不清楚周转期。
-我们还使用 EMIF 接口进行了测试,这导致了进一步的问题。
该接口在 37.5MHz 频率下运行、相关的配置寄存器 (CE2CFG) 设置为值 0x04142111U。
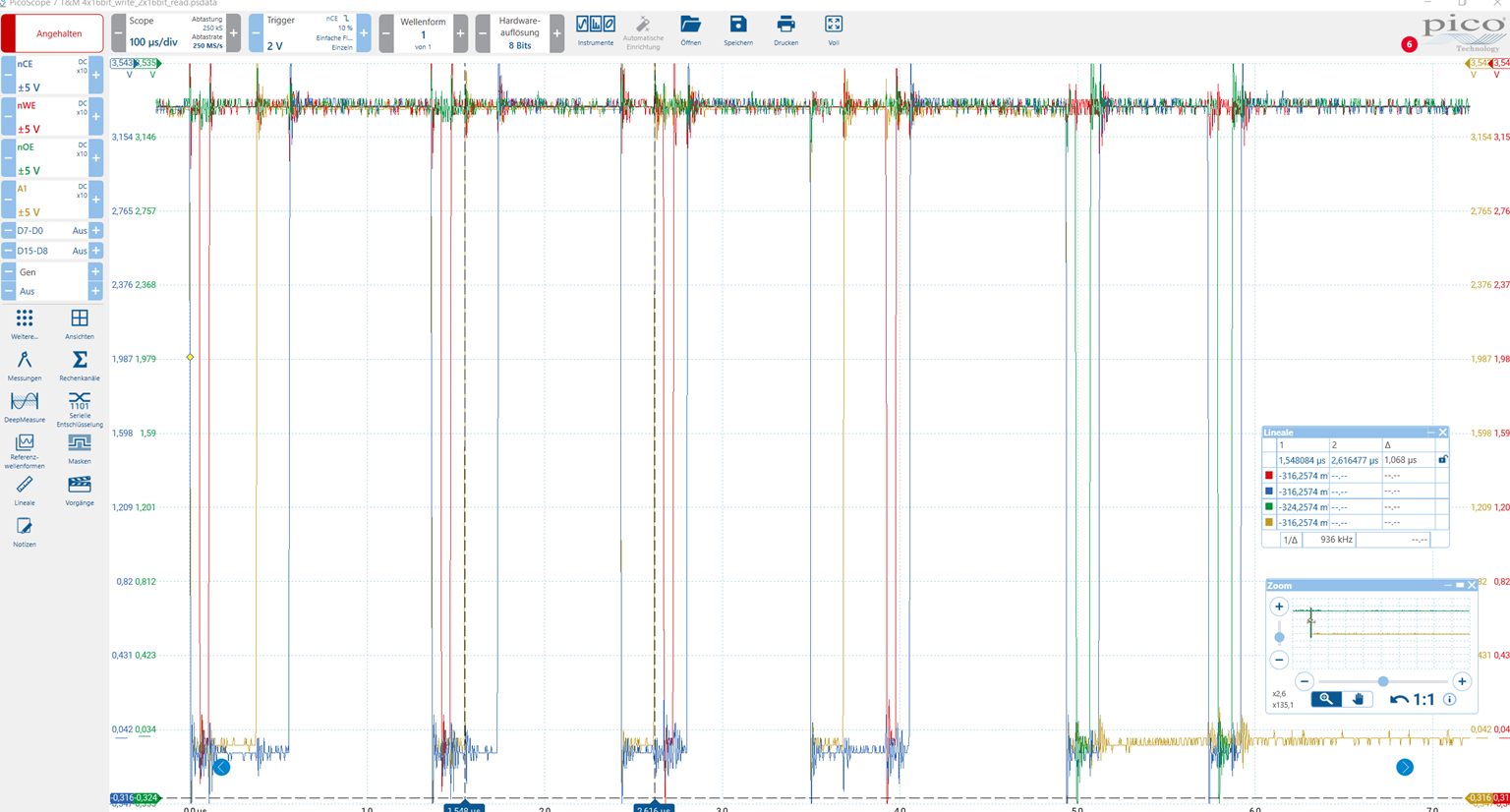
以下记录显示了四个 16 位写入访问、后跟两个 16 位读取访问:
为此执行了以下代码: 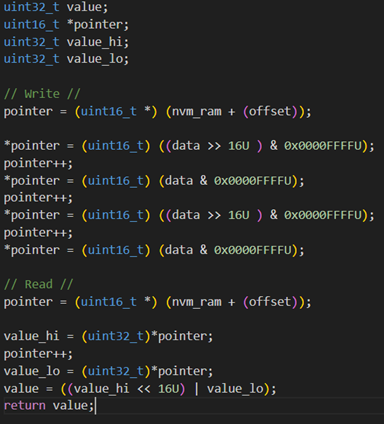
这两个读取访问按预期显示、但这四个写入访问看不到。
值得注意的是、片选的拉取时间要早得多、或者拉取时间要比需要的时间长得多。
地址位 A1 的行为也并非总是如 TRM 中所述。
µs、各个访问之间的时间非常长、在 613ns 和 1.068 μ s 之间变化(请参阅标尺)。
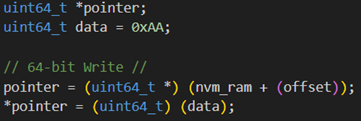
进行了另一项测试、这次使用 64 位写入访问: 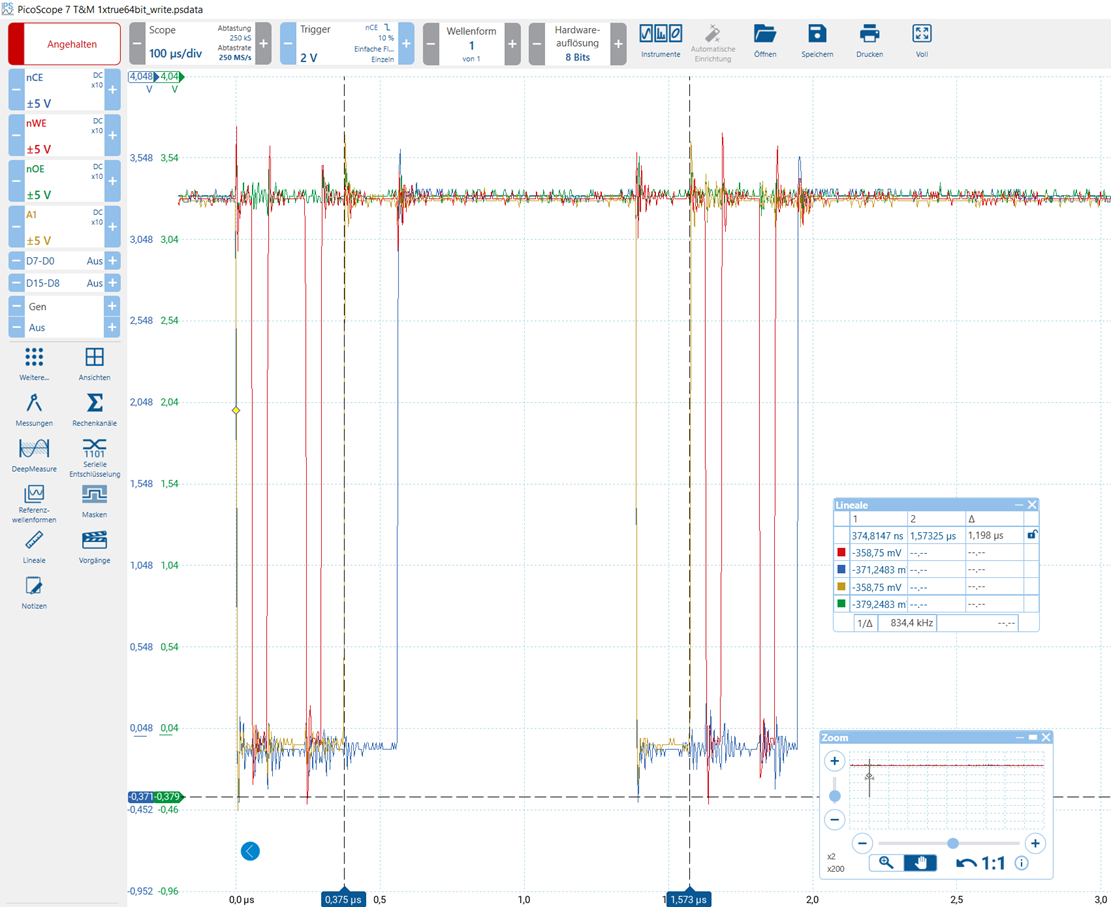
正如 32 位架构预期的那样、该访问分为两个 32 位访问。
每个 32 位访问似乎包含两个直接串在一起的 16 位访问。
µs、此测试再次显示两个 32 位访问之间的时间非常长 (1.198 μ s)。
出现的问题:
-如何解释写访问期间芯片选择的行为,这可以与来自 TRM 的信息协调?
-是否有一种方法可以缩短各个 16/32 位访问之间的长等待时间,以实现更高的有效数据速率?

