请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TM4C129XNCZAD 主题中讨论的其他器件:SEGGER、 DK-TM4C129X、 EK-TM4C1294XL、 EK-TM4C129EXL、 MSP-EXP432E401Y、 MSP432E401Y
您好!
我们一直在努力解决一个非常奇怪的硬故障、这种故障要么在相同条件下的一段时间后发生、要么从未发生(取决于编译输出)。
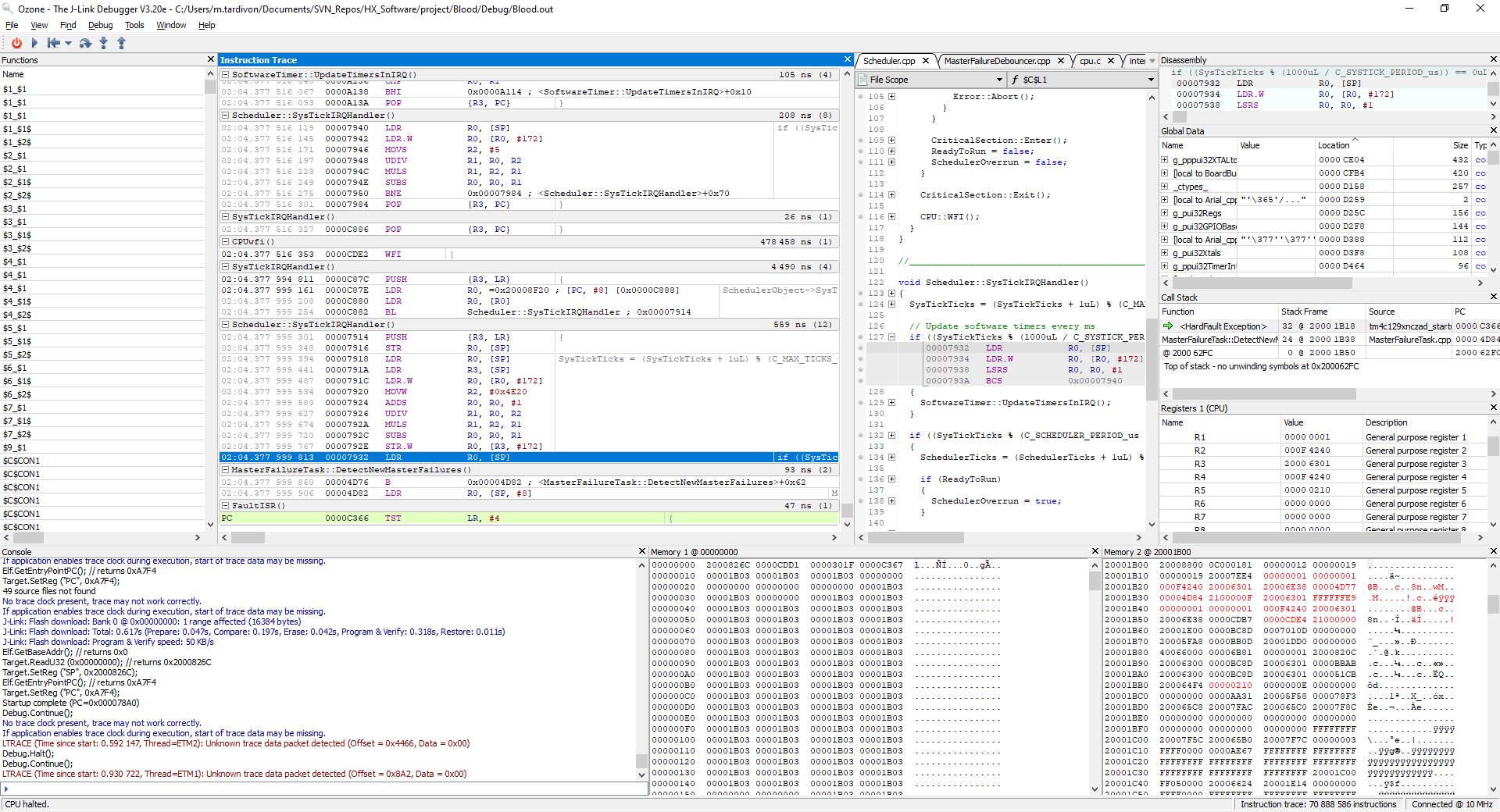
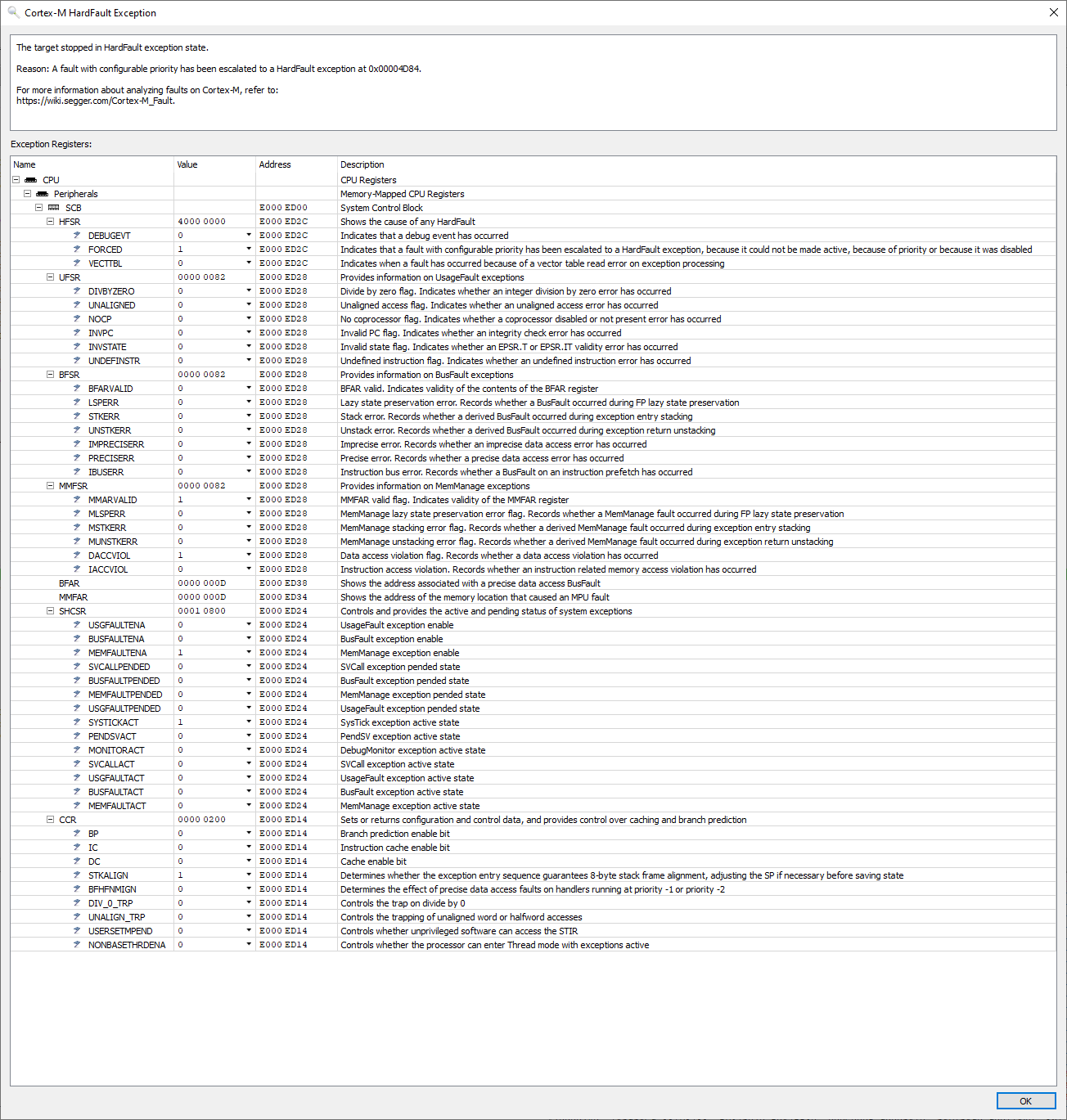
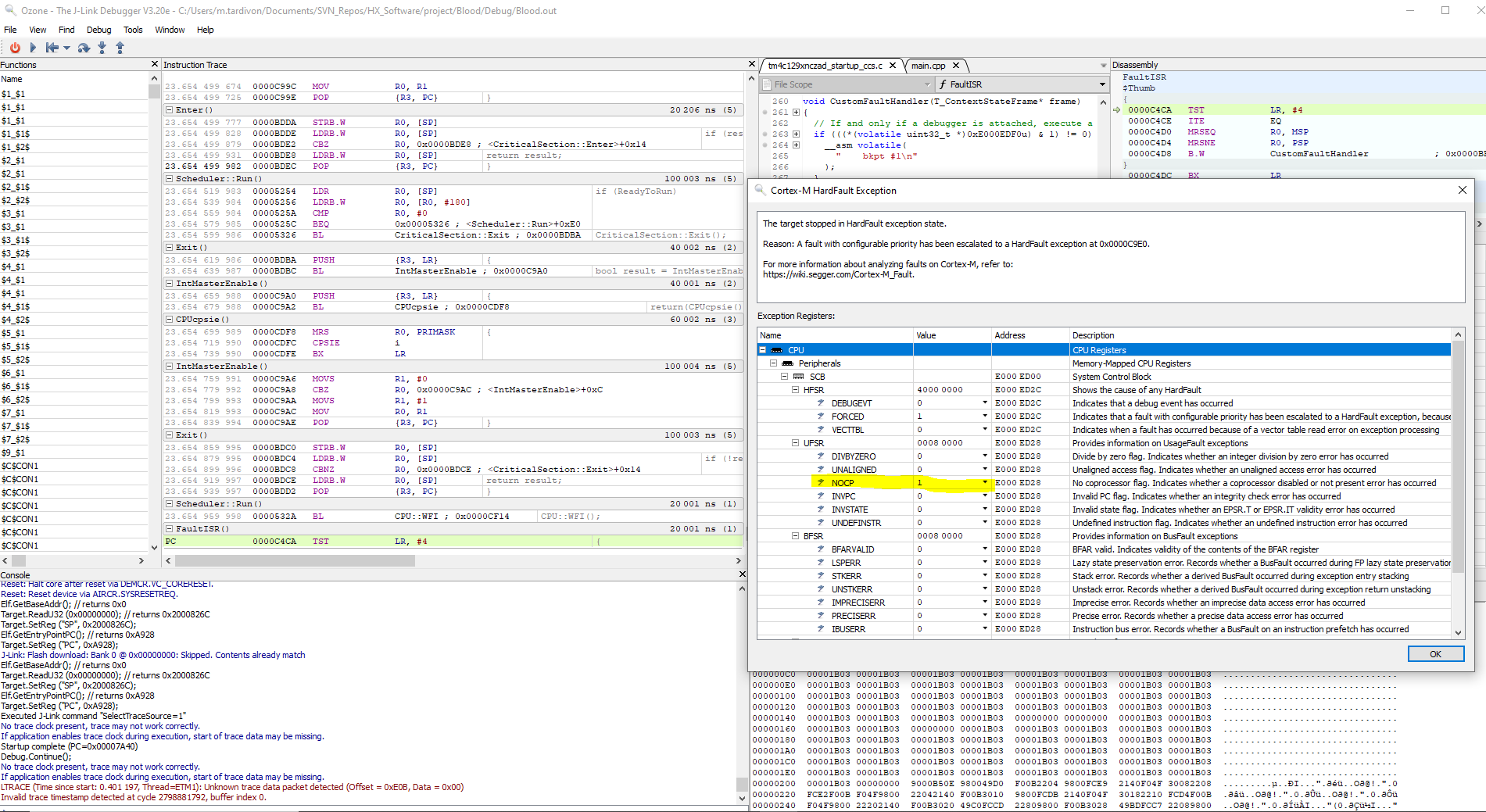
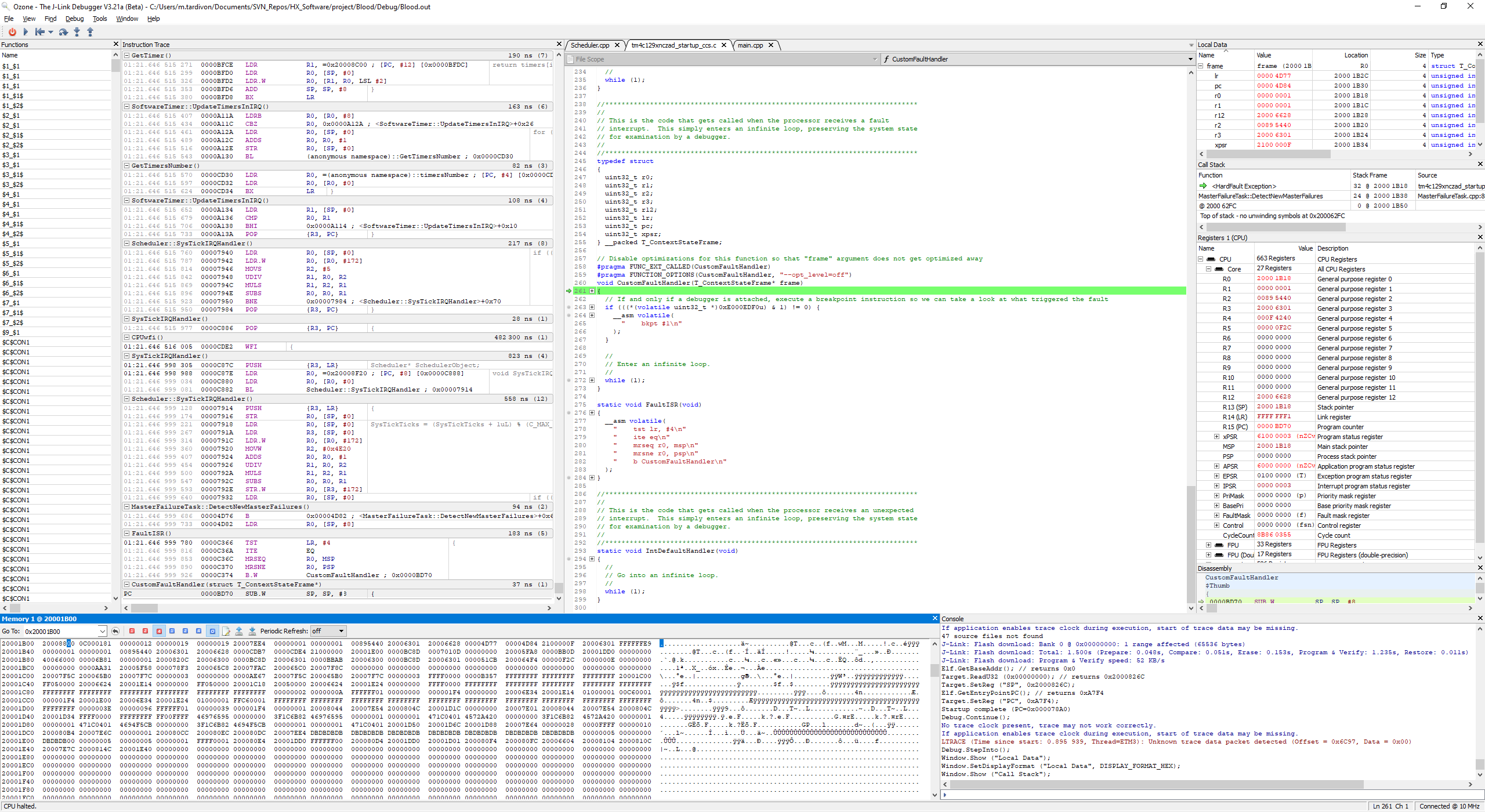
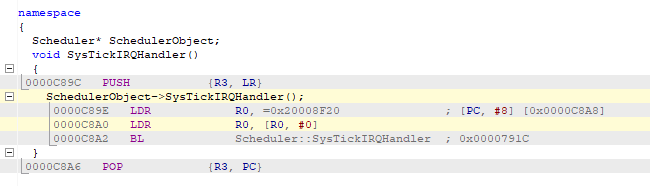
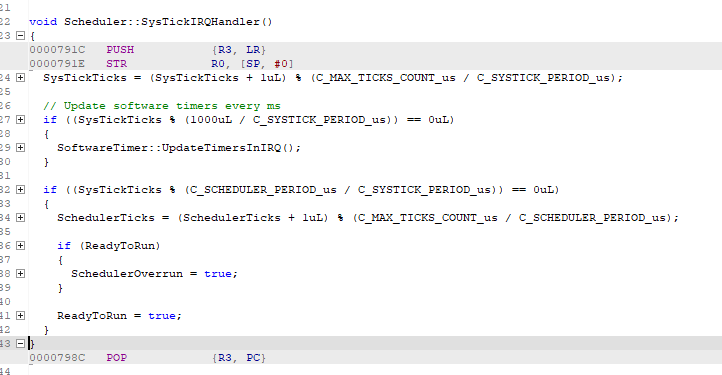
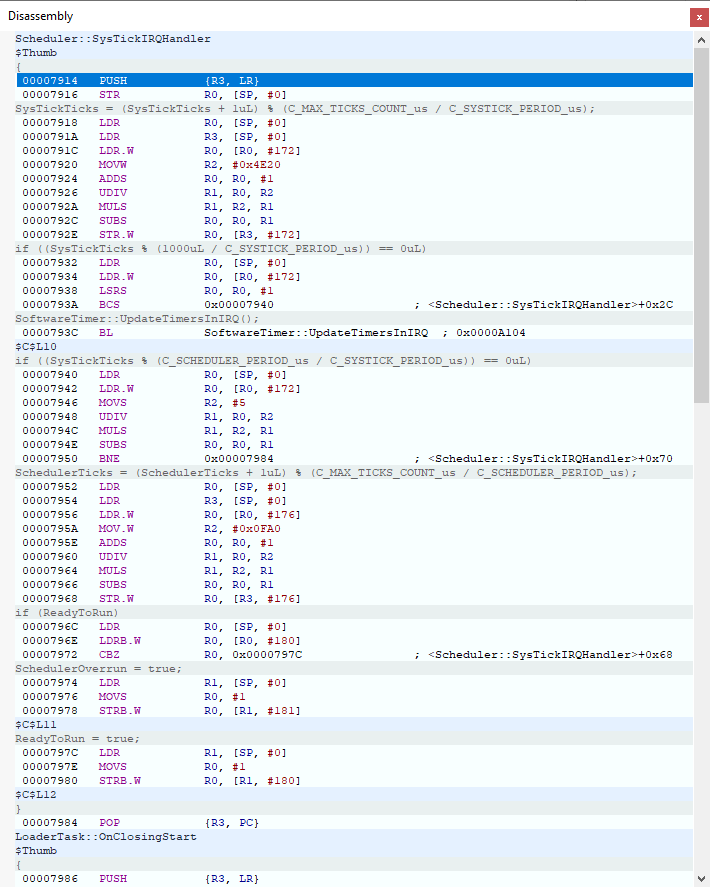
我们投资了一款用于 Cortex M 的 J-Trace Pro 并执行了指令跟踪、我们观察到了最奇怪的行为。 在某个指针处、在中断处理程序中、PC 不仅在一条简单的寄存器加载指令后递增、而且会跳转到代码的完全不同部分。
您是否经历过这样的行为? 勘误表中是否有我可能遗漏的内容?
请在下面找到进入硬故障处理程序时指令跟踪的屏幕截图: