请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:DK-TM4C129X
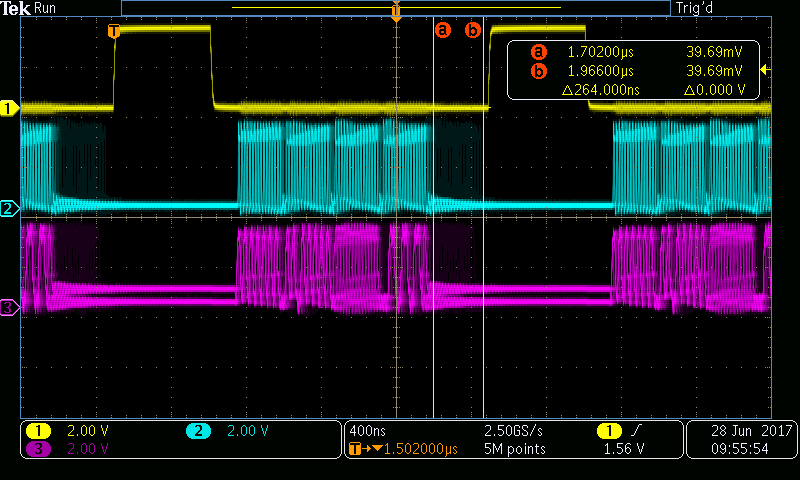
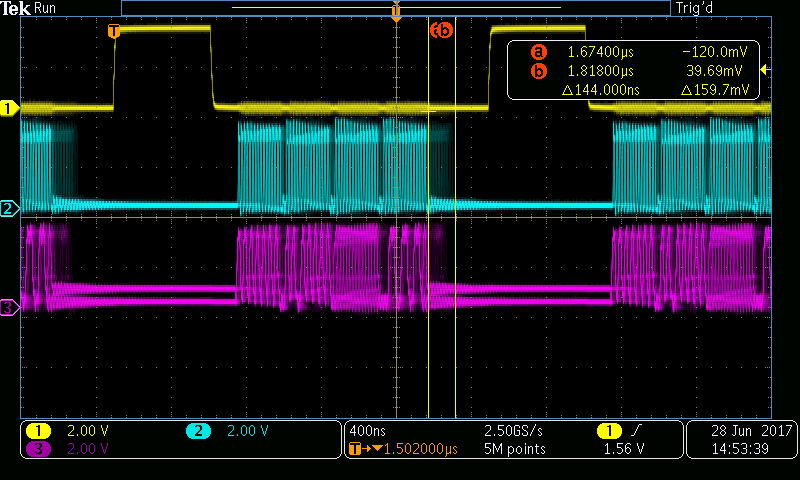
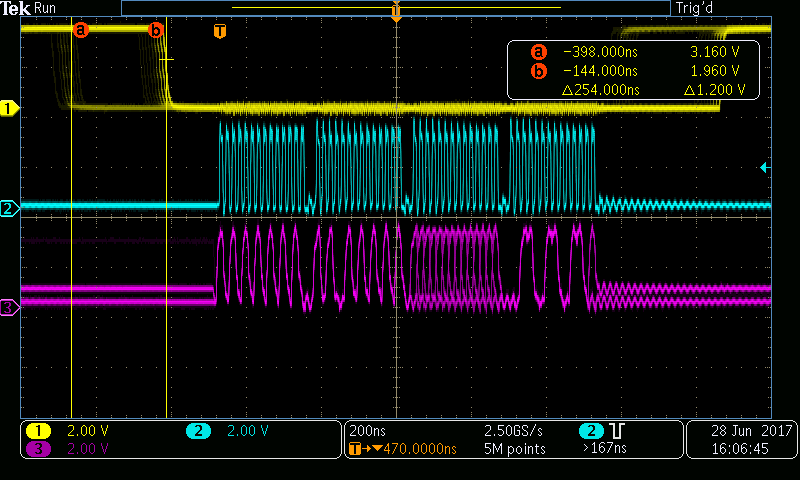
我有一个应用程序、它将一组散聚 µDMA 的持续忙状态保持在大约30Mbit/s DMA 似乎正常工作。 当我通过 TI-RTOS 堆栈通过以太网开启30Mbit/s 的传输时、DMA 的抖动增加了约400ns。 这在我的设计中是可以容忍的、但不可取的、因为它是一个性能限制因素。 为了尽量减少以太网操作引起的抖动、我设置了
HWREG (EMAC0_BASE_EMAC_O_DMABUSMOD)= BFM (HWREG (EMAC0_BASE_EMAC_O_DMABUSMOD)、1、EMAC_DMABUSMOD_PBL_M);
HWREG (EMAC0_BASE_EMAC_O_DMABUSMOD)|= EMAC_DMABUSMOD_FB
"BFM"将 PBL 位域的值设为1。
在该设置下、抖动为400ns。 我还没有查看堆栈源以了解这些字段是如何处理的、可能是频繁过载并使我的努力无效。
相对于 μ µDMA、EMAC 的 DMA 优先级是多少? 是否可以将其设置为低于 µDMA Ω?