Other Parts Discussed in Thread: AM2632, SYSCONFIG
主题中讨论的其他器件: SysConfig
工具与软件:
我想将计算代码放置在 TCMA 中、并根据示例例例例程进行了以下修改:
添加了代码:
.TI.local:{}>> R5F_TCMA | R5F_TCMB | OCRAM
.TI.onchip:{}>> OCRAM | FLASH
.TI.offchip:{}> flash
放置在以下代码之前:
/* C++项目所需的部分/
组{
.arm.exidx:{}palign (8)/ C++异常处理需要/
.init_array:{}palign (8)/包含在 main /之前调用的函数指针
fini_array:{}palign (8)/包含在 main */}> OCRAM 之后调用的函数指针
在编写函数时、将其声明为:
(__LW_AT__因为我的程序目前使用的是定点计算、所以转换为浮点是一项艰巨的任务、所以我暂时使用了 AM2632)上的 DSP IQmath 库
_iq24 attribute((local(1))) _IQ24mpy1(_iq24 A, _iq24 B)
{
_iq24 result;
asm volatile(
"smull r2, r3, %1, %2
"
"lsr r2, r2, #24
"
"lsr r3, r3, #8
"
"add %0, r2, r3
"
: "=r" (result)
: "r" (A), "r" (B)
: "r2", "r3", "cc"
);
return result;
}
当我运行它时、代码仍然在 RAM 中执行、而不是在 TCMA 中执行。TCMA 中的执行可通过反汇编检查地址来验证。
_IQ24mpy1():
7004dd74:FB802307 smull R2、r3、r0、r7
7004dd78:EA4F6212 LSR.w R2、R2、#0x18
7004dd7c:EA4F2313 LSR.w R3、R3、#8
7004dd80:EB020003 add.w r0、R2、R3
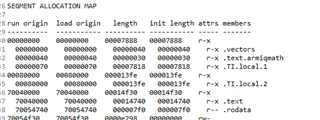
我比较了 示例的 linker.cmd 与我的项目、它们几乎完全一样。 我的调试构建生成的映射文件不包含函数_iq24mpy1、而示例例例例程生成的映射文件包含以下代码段。
.irqstack
* 0 70057a08 00000100 UNINITIALIZED
70057a08 00000100 --HOLE--
.fiqstack
* 0 70057b08 00000100 UNINITIALIZED
70057b08 00000100 --HOLE--
.svcstack
* 0 70057c08 00001000 UNINITIALIZED
70057c08 00001000 --HOLE--
.abortstack
* 0 70058c08 00000100 UNINITIALIZED
70058c08 00000100 --HOLE--
.undefinedstack
* 0 70058d08 00000100 UNINITIALIZED
70058d08 00000100 --HOLE--
.init_array
* 0 70040000 00000000 UNINITIALIZED
.TI.local
* 0 00000040 00001c06
00000040 00000802 basic_smart_placement.o (.text.annotated_function_f2)
00000842 00001002 basic_smart_placement.o (.text.annotated_function_f3)
00001844 00000402 basic_smart_placement.o (.text.annotated_function_f4)
我的地图文件包含以下内容:
.irqstack
* 0 70059ca0 00000100 UNINITIALIZED
70059ca0 00000100 --HOLE--
.fiqstack
* 0 70059da0 00000100 UNINITIALIZED
70059da0 00000100 --HOLE--
.svcstack
* 0 70059ea0 00001000 UNINITIALIZED
70059ea0 00001000 --HOLE--
.abortstack
* 0 7005aea0 00000100 UNINITIALIZED
7005aea0 00000100 --HOLE--
.undefinedstack
* 0 7005afa0 00000100 UNINITIALIZED
7005afa0 00000100 --HOLE--
.init_array
* 0 70040000 00000000 UNINITIALIZED
.trigText
* 0 00000040 00000594
00000040 00000594 mathlib.am263x.r5f.ti-arm-clang.release.lib : ti_arm_trig.obj (.trigText)
.trigData
* 0 000005d8 000000b0
000005d8 000000b0 mathlib.am263x.r5f.ti-arm-clang.release.lib : ti_arm_trig.obj (.trigData)
为什么? 如何将我的代码放入 TCMA?