This thread has been locked.
If you have a related question, please click the "Ask a related question" button in the top right corner. The newly created question will be automatically linked to this question.
https://e2e.ti.com/support/microcontrollers/arm-based-microcontrollers-group/arm-based-microcontrollers/f/arm-based-microcontrollers-forum/1416819/am2431-ethernet-performance
工具与软件:
大家好、TI 专家!
https://software-dl.ti.com/mcu-plus-sdk/esd/AM243X/latest/exports/docs/api_guide_am243x/enetlld_performance.html。
根据上面的链路、在使用数据长度为1470字节的 AM243-LP 使用 iperf 进行测试时、最好的 RX 速度可达110Mbps。 这是否意味着、尽管 AM243支持千兆位以太网速度、但 MCU 本身无法在一秒内处理千兆位数据?
此致、
Larry
Larry、您好!
感谢您的提问。
您似乎正在处理最新的 AM243x MCU+SDK。
您正在使用哪个端口 ICSSG 或 CPSW?
SDK 中的示例没有可获得卓越性能的工程设置。
以下是客户可以根据用例优化性能的一些点。
请告诉我您尝试实现的用例或最终目标?
此致
Ashwani
尊敬的 Ashwani:
感谢您的答复、
我使用的是 CPSW 端口1。
在我的应用中、服务器向 AM2431发送原始以太网数据包。 每个数据包为1461字节、数据包间隔约为5微秒。 最大数量是每个周期8640个数据包、随后等待20ms 再发送。 所有数据包都会被广播。
我曾尝试添加更多数据包缓冲区、但 syscfg 中有一个限制、即数据包池大小只能达到192、这与我的目标相差甚远。
您能解释一下您的其他选择吗?
谢谢你。
Unknown 说:所有数据包均广播
您使用的是应用/示例调试还是发布模式?
您使用的是交换机模式还是 MAC 模式?
传入到主板的数据包是否启用了 VLAN 和优先级?
如果有、那么数据包的优先级是什么?
如果您的 case 有突发流量。 您是否可以尝试使用以下 IOCTL 调整到达主机的流量?
我在 Debug 和 Release 模式下进行了测试、但没有看到任何改善。
我使用的是 MAC 模式。
否、我未启用 VLAN 和优先级。 我的应用程序需要接收所有数据包并解析其内容、以决定是否绕过或处理它们。
我想知道、由于我的应用传输原始以太网数据包、使用此函数是否会导致数据包丢弃或停留在某个缓冲区中?
谢谢 Lary、
Unknown 说:每个数据包为1461字节、数据包间隔约为5微秒。 最大数量是每个周期8640个数据包、随后等待20ms 再发送。 所有数据包都会广播。[/QUOT] 这样、您就在 CPSW 端口上工作、具有 UDP 广播帧+双 MAC 模式。 单播帧(定向到主机)是否获得相同的结果? [报价 userid="574777" url="~/support/microcontrollers/arm-based-microcontrollers-group/arm-based-microcontrollers/f/arm-based-microcontrollers-forum/1416819/am2431-ethernet-performance/5428025 #5428025"] 您能解释一下您的其他选择吗? 堆栈放置 数据包缓冲区放置 整体存储器放置 [报价] 当您在使用 AM234x-LP 时、我假设您的所有设备都只存在于 MSRAM 中。 同时、我将在内部检查我们是否可以建议您一些东西来获得比 AM243x MCU+ SDK 更好的性能:以太网性能(TI.com)。 此致 Ashwani
这样、您就在 CPSW 端口上工作、具有 UDP 广播帧+双 MAC 模式。
单播帧(定向到主机)是否获得相同的结果?
当您在使用 AM234x-LP 时、我假设您的所有设备都只存在于 MSRAM 中。
同时、我将在内部检查我们是否可以建议您一些东西来获得比 AM243x MCU+ SDK 更好的性能:以太网性能(TI.com)。
很抱歉延迟重播、
实际上、我不使用 UDP;我的应用用的是原始以太网数据包。
在单播模式下、一切都运行良好、因为负载不如广播模式那么重。 它只接收它需要的数据、但我仍然需要广播模式才能工作。
Unknown 说:在单播模式下、一切运行良好
感谢 Larry 更新。
单播交换也应获得相同的性能。
但是、广播帧需要切换到另一个端口并被主机消耗。 因此、整体性能降低。
但我使用外部以太网交换机、因此 AM2431不需要处理端口之间的切换帧。 它只需要从一个端口接收帧、如果需要、还会将帧发送到该端口。 这是否仍会消耗大量的处理时间?
此致。
Unknown 说:外部以太网交换机
好了、您的设置如下:
AM243x<=>外部开关<=> PC
PC 正在发送广播帧。
所以、我的假设是所有碎片也会传入 AM243x 端口。
它会转发到 AM243x 的另一个端口和主机端口。
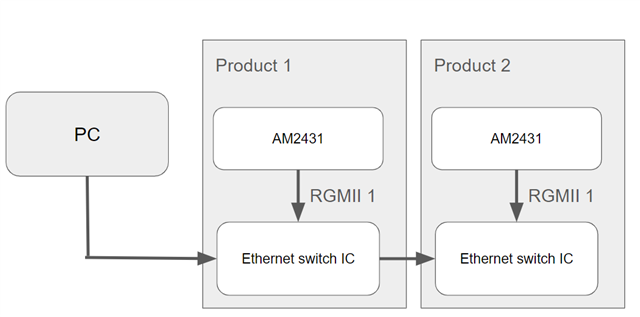
我来解释一下细节。 AM2431使用连接到外部以太网交换机 IC 的 RGMII-1接口、因此所有帧都通过该端口进行通信。
根据您的描述、即使我不尝试向另一个端口发送帧、它也会自动发送到端口2。 这是否仍会消耗 MCU 处理时间? 即使未连接端口2、MCU 是否仍会花时间尝试从其接收帧?
您能否确认设置?
端口1和端口2上连接了什么?
您能分享一下方框图以便更好地理解吗?
我使用的 AM2431通过 RGMII 接口连接到外部以太网交换机 IC。 根据下面的 syscfg、我将 RGMII 1用于 CPSW、因此我认为我的以太网交换机连接到端口1、而没有使用端口2。
我来回顾一下、下周同一时间再见。
这方面是否有新的进展?
感谢您的耐心。
我在内部讨论了这一点、但尚不清楚 每个产品是否真的需要在单个 MAC 端口上使用 BC 帧。
或者
PC 正在发送特定帧、需要由特定 AM243x 使用?
product-1-CPSW 端口正在接收并恢复相同的帧、该帧也将转至下一个 Product-2-CPSW 端口。 是故意的吗?
如果没有、您是否能够使用 MC 帧并进入 CPSW-ALE、以通过特定产品(主机)使用特定的数据包。
如果您使用 BC 数据包、本地(主机) Rx 性能将受到影响、因为它将增加连续的并行本地 Rx / Tx 处理。
Unknown 说:即使我不尝试向另一个端口发送帧、它也会自动发送到端口2
如果在 SysConfig 中禁用另一个端口、则不会转发到另一个端口。
基本上、CPSW IP 支持1G 切换到另一个端口、而不是主机 Rx。
我们正在努力改进我们本地的 Rx / Tx 性能基准数字。
充当控制器的 PC 出于各种目的发送不同的帧。 我可以发送 MAC 帧、运行良好、但其中一个条件需要发送广播帧以提高效率、因此我将尝试实现它。
当产品1中的以太网 IC 接收到帧时、它会自动将其传输到 AM2431主机端口和产品2。 它不需要 AM2431参与。
我对这一点很好奇:这是否意味着 CPSW 在将帧传输到端口2时只能处理高达1G 的帧、而不能处理主机端口? 硬件接口是 RGMII、我认为这是1G 速度接口。 从我到目前为止的实验中、我假设 AM2431主机端口可以1G 速度接收和传输帧、但它无法在1秒内处理1Gbit 的数据。 您能否确认这一点?
Unknown 说:产品1中的以太网 IC 收到帧时、它将自动将帧传输到 AM2431主机端口和产品2
因此、对于 Portec-1:您希望 AM243x 使用 BC 帧。 无需发送回产品1的以太网交换机。 对吗?
Unknown 说:无需 AM2431参与此事。
AM243x 对产品2的期望是什么? 与 product-1类似?
Unknown 说:从到目前为止的实验中、我假设 AM2431主机端口可以1G 速度接收和传输帧、但它无法在1秒内处理1Gb 数据。 您能否确认这一点?
我需要在内部查看这一点并与您联系。
正确。
Product-2与 Product-1类似。 BC 帧将携带信息、使他们能够识别属于他们的捕获内容。 在我们的用例中、整个系统中的菊花链中有10到数百个产品。
你好 、Larry Chen、
我上周在度假。 因此无法对此进行检查。
我们下周同一时间再见。
大家好、 Larry Chen、
总之、您以菊花链形式拥有多个基于 AM243x-EVM 的定制电路板。
PC<=> custom-board-1<=> custom-board-2 <=> custom-board-3
定制电路板具有 AM243x-EVM +开关
现在、您将从 PC 发送 uC +BC 帧。
使用 uC 帧、您将在 AM243x-EVM 上获得预期的性能。
当 BC 帧也包含在流量中时、您会面临性能问题?
您能帮助我测试案例吗(您如何测量 UC 和 BC 帧的吞吐量)?
您在哪里检查 PC、交换机或 R5F-Host 的吞吐量?
很抱歉响应延迟;我最近忙于其他项目。 我们的产品主要侧重于显示图像、因此当接收到数据包时、将对其进行解析并显示图像内容。 根据图像的显示状态、我可以轻松地确定是否存在任何传输问题。
此外、我做了另外一个实验:收到一个数据包、将 GPIO 管脚设置为高电平、处理后将 GPIO 管脚设置为低电平。 通过逻辑分析仪(LA)观察该 GPIO 引脚、可以明显看出、根据我配置的以太网缓冲区大小、每个图像数据包为1518字节。 定期查看、我可以看到 GPIO 引脚被设为高电平的次数对应于以太网缓冲器大小除以1518。
这表示当任务检查 DMA 缓冲区时、它只处理 DMA 缓冲区可以接收的数据包。 但是、当我的 PC 发送广播(BC)帧时、总数明显大于 DMA 缓冲区可以处理的最大大小。 因此、我得出结论、AM243可能无法满足我们对有效处理大量数据的要求。
在 PC 中、我使用 Wireshark 来监控发送和接收的数据包。
感谢 Larry、
根据您的用例、AM243x 预计要处理的总流量速率是多少?
它似乎只是层通信处理和通信速率也很低。 都应该可以与 AM243x 搭配使用。
您是否与某些 TI 现场团队(FAE)有联系?
默认的数据包处理方法是基于中断的。
您可以使用"轮询方法"而不是中断切换到"批处理"。
还可以在 example.syscfg 中尝试增加缓冲区计数。
我们的产品要求每幅图像13,824字节、大约每30毫秒发送一帧。 因此每秒需要33帧。 对于总共200个模块的更大系统估算值、计算方法如下:
13,824 * 8 * 33 * 200 = 729,907,200位/秒
在 BC 模式下、每个模块将需要处理729 Mbps 的数据。 这是我想要达到的性能水平。
我会尝试在我这边联系 FAE。 您可以使用"轮询方法"而不是中断切换到"批处理"。
您能解释一下如何将 "批处理"与"轮询方式"结合使用吗?
我不再使用中断来处理数据包。 相反、我使用一个计时器以大约1ms 的间隔定期检查以太网缓冲区。
我尝试将大型池包计数增加到其最大值、但仍然不足以处理负载。
Unknown 说:每个模块需要处理729 Mbps 的数据。 这是我想要达到的性能水平。
并且当前速率为110Mbps。
目前、加载了多少 CPU (R5F 内核)?
我将在内部讨论这一点、然后回复给您。
Unknown 说:我将尝试与 FAE 联系。
我们期待与您同步。
由于我们使用的是 AM-2431、因此我们只能使用一个内核。
Unknown 说:如何将 "批处理"与"轮询方式"结合使用? [报价] 为方便起见、您可以参考"C:\ti\mcu_plus_sdk_am64x_10_00_00_20\examples\networking\lwip"位置的 LwIP 网络示例。 此致 Ashwani
为方便起见、您可以参考"C:\ti\mcu_plus_sdk_am64x_10_00_00_20\examples\networking\lwip"位置的 LwIP 网络示例。