

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TMS320F28034 您好、香榭丽舍
我向我们的客户询问这一点。
客户发现、在使用 IQMath23进行计算时、负数的精度低于正数。 我用 F28069测试了它、我可以重现客户的问题。
例如,如果计算-0.00001*0.99,则计算结果与-0.00001*1相同。
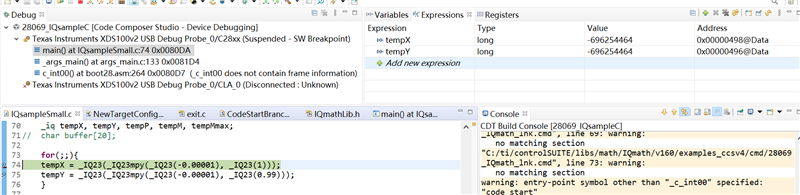
但是如果它是0.001*0.99,则计算结果将会不同。
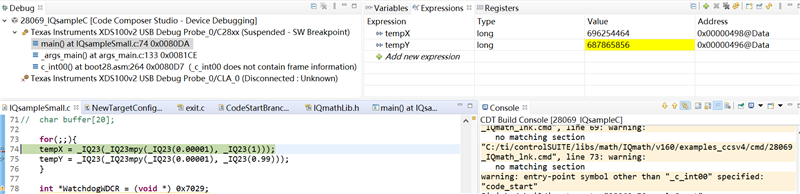
您能否帮助解释这种差异的发生原因? 谢谢!
此致、
Julia
