请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TMS320F28377S 您好!
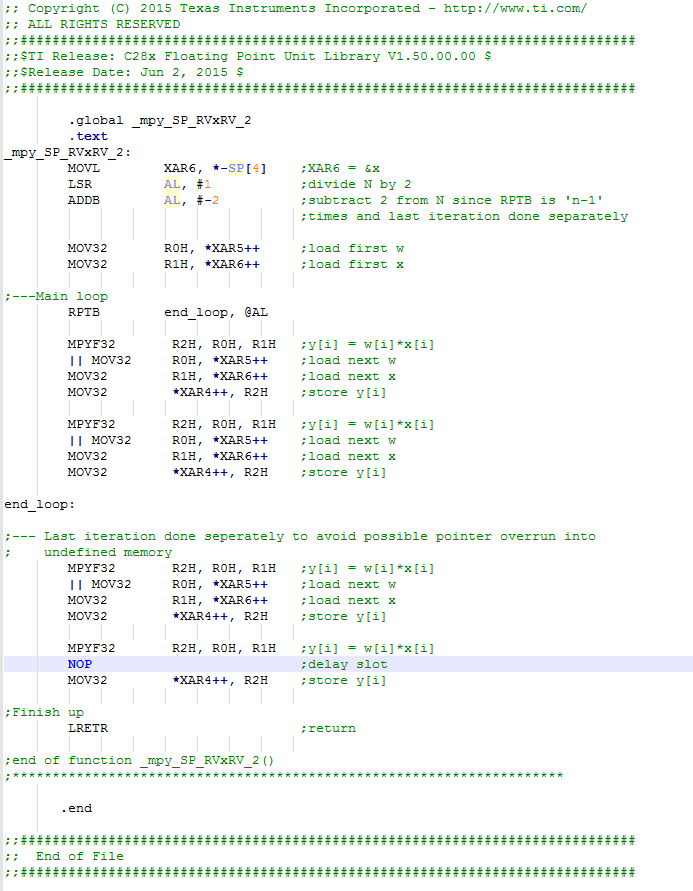
FPU 库提供了面向按元素进行向量乘法的 C 语言可调用汇编函数(点积、相关代码片段在线程末尾以屏幕截图形式给出)。 我还在寻找 矢量乘法的 C 可调用汇编、如图1所示、该汇编在末尾提供了一个单一元素

图1. 矢量乘法
FPU 库中提供的矢量乘法函数具有以下函数名:void mpy_SP_RVxRV_2 (float32 * y、const float32 * w、const float * x、const UINT16 N)
我正在寻找类似的东西:float32 function_name (const float32 *w、const float *x、const uint16 N)
将有一个返回、给出所有元素按向量乘法的总和。