请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
您好
我们研究系统中的实时问题。
主要思路是测试任务对中断的响应时间(通过信标端口)并测量任务唤醒时间中的抖动。
设置:
125us 的中断、将信标布置到任务、随后发布另一个信标。
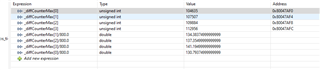
在2个位置/任务中对 CPU 时间戳计数器进行采样。 进行一次发送。
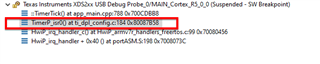
我们总共有2个跃点、即从 ISR 发布的信标、任务唤醒、采样时间、并且将信标布置到下一个较低优先级的任务、再进行采样。
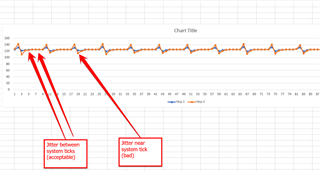
我们将测量表示任务唤醒中抖动的时间戳差异。
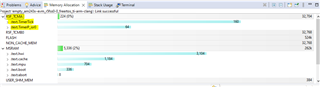
随着每个新的"跳"抖动的增加、系统节拍(1毫秒)和抖动之间存在明显的相关性。
看起来 Tick 通知花费太多的时间或者 CPU 只是很慢。
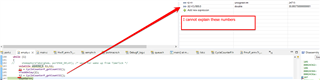
我已检查 DDR 已缓存且两个 I/D 缓存均已打开。
是否可以检查 SOC 配置、是否可能某些 PLL/频率设置不正确?