请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
部件号:MSP430FR5739 我正在尝试确定在轮询循环期间轮询GPIO输入和设置GPIO输出时,为什么会看到比预期延迟更大的延迟。 (注: 我意识到以这种方式轮询输入通常是不能的; 但是,出于讨论的目的,将下面的代码 按现状读取) 作为记录,我找不到一个确切的测量方法来衡量读取引脚并根据该引脚的状态设置GPIO所需的时间。 无论如何...
时钟系统设置为接受XIN上TCXO的16MHz。
WFP 2.3 连接到一个信号发生器,10Hz @10 % 占空比。
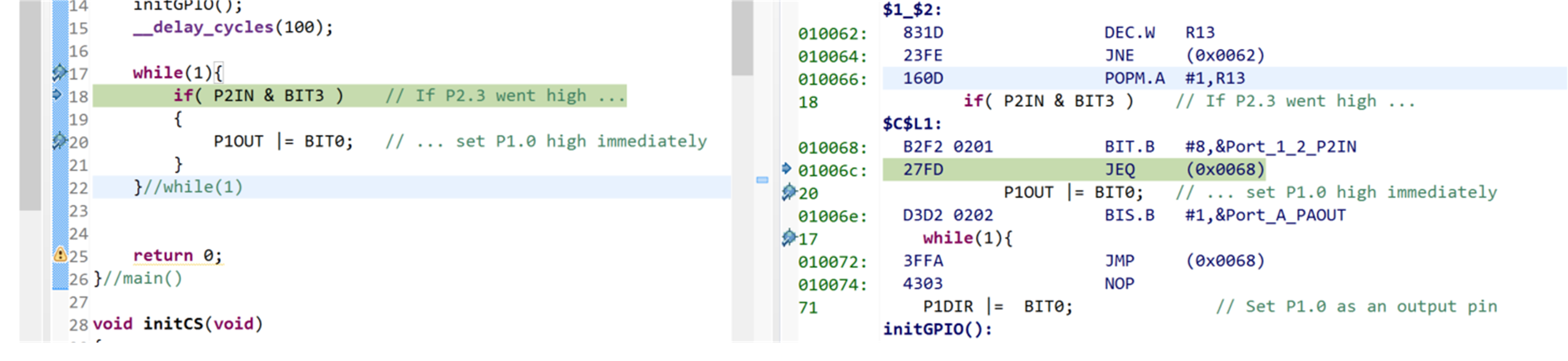
WFP 2.3 被设置为启用下拉电阻器的输入端口。 PIN 1.0 设置为输出。 当WFP 2.3 变高(按一下按钮)和WFP 1.0 之间 ,我看到的延迟时间是 620秒。 由于我的MCLK 周期是62.5毫秒 ,因此需要大约9个MCLK周期来读取PIN并设置WFP 1.0。 这对我来说似乎太过分了,我无法判断我看到的行为是否是预期行为。
#include <msp430fr5739.h>//
原型
void initCS(void);
void initGPIO (void);
int main(void)
{
WDTCTL = WDTPW | WDTHOLD;// stop watchdog timer
initCS();
initGPIO ();
__DELAY周期(100);
而(1){
If( P2IN & BIT3)//如果WFP 2.3 高...
{
P1OUT || BIT0;//...立即将WFP 1.0 设置为HIGH
}
}//while (1)
返回0;
}//main()
void initCS(void)
{
PJSEL0 |= BIT4; //将PJ.4设置为Xin,数字方波输入
PJSEL1 &=~BIT4;
CSCTL0_H = 0xA5; //解锁用于更新CS的密码
/CSCTL1 |= //不关心此寄存器,不使用DCO
CSCTL2 = SELM__XT1CLK + SELS__XT1CLK +拉美经济体系__XT1CLK;// MCLK SOURCE = XT1CLK;SMCLK SOURCE = XT1CLK;
// ACLK源= XT1CLK
CSCTL3 = DIVM__1 + DIVs__2 + DIVA__32; // MCLK/1;SMCLK/2;ACLK/32
CSCTL4 |= XT1BYPASS | XTS | XT2OFF; //选择旁路模式操作
//对于XT1;选择高频率模式;
//不需要XT2,因此请将其关闭
做
{
CSCTL5 &=~XT1OFFG; //清除XT1故障标志
SFRIFG1 &=~OFIFG;
__DELAY周期(1万); //等待片刻,然后再进行下一项检查
} 同时(SFRIFG1&OFIFG); //测试振荡器故障标志
PJDIR || BIT5; //将PJ.5设置为GPIO输出(不需要XOUT)
PJDIR || BIT0; //将PJ.0设置为SMCLK输出
PJSEL0 |= BIT0;
PJSEL1 &=~BIT0;
PJDIR || BIT1; //将PJ.1设置为MCLK输出
PJSEL0 |= BIT1;
PJSEL1 &=~BIL1;
PJDIR |= BIT2; //将PJ.2设置为ACLK输出
PJSEL0 |= BIT2;
PJSEL1 &=~BIIT2;
}//initCS()
void initGPIO (void){
//脉冲输出引脚WFP 1.0
P1DIR || BIT0; //将WFP 1.0 设置为输出引脚
P1OUT &=~BIT0; //将WFP 1.0 初始化为低
//同步感应引脚WFP 2.3
P2DIR &=~BIT3; //将WFP 2.3 设置为输入引脚
P2REN |= BIT3; //在此引脚上启用PU或PD
P2OUT &=~BIT3; //选择此引脚上的下拉电阻器
__DELAY周期(5); //给出时间让上拉稳定
}

(1)编译器设置(调试与发行模式)与此延迟是否有任何关系?
(2)是否有办法降低此延迟?
(3)破纪录,使用中断设置WFP 1.0 会导致WFP 2.3 高和1.0 高之间的延迟时间更长。