请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:MSP430FR5969 主题中讨论的其他器件:MSP-EXP430FR5969
工具/软件:Code Composer Studio
尊敬的所有人:
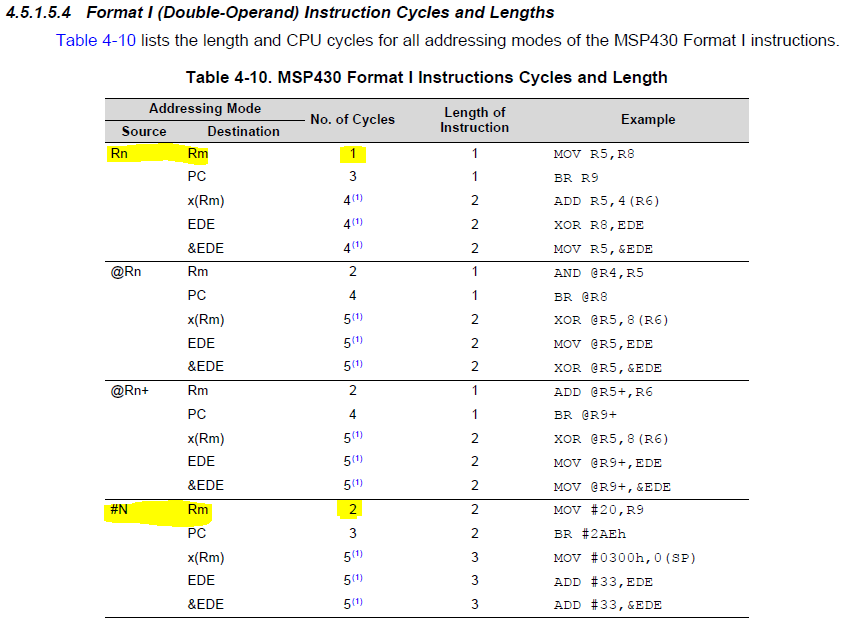
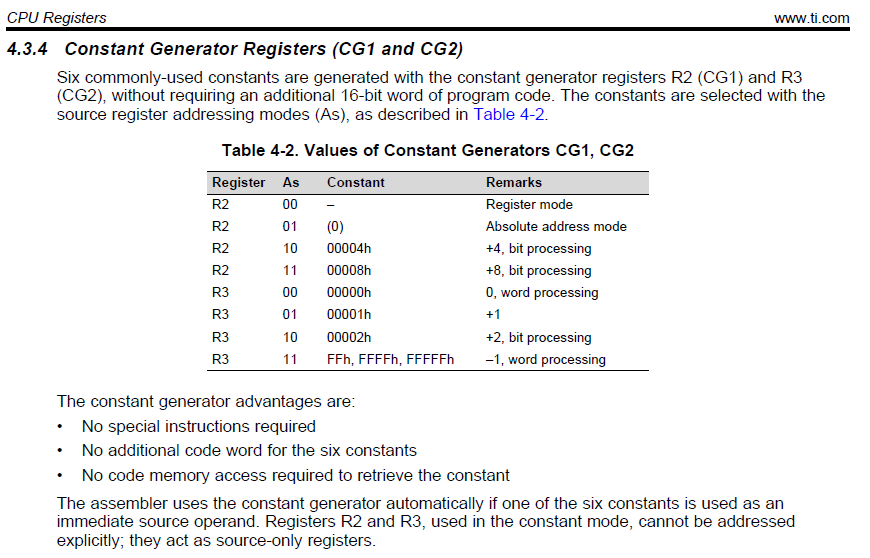
我使用汇编语言、需要计算准确的编码时序。 我看不到这些代码之间的差异、但根据作者、它们需要不同的周期才能运行
MOV#dataBuf、R12;[2]载入&dataBuf[0] MOV#DATABUFF_SIZE、R13;[1]载入到 Corr reg (numBytes)
MOV #TX_时序_ACK、R5 ;[2]
而 dataBuf 声明为 uint8_t dataBuf[30]、而 DATABUFF_SIZE 和 TX_时序_ACK 定义为常量。 []中的数字是要执行的代码的周期数。
我找到了 TI 的指令集摘要。 但我对我正在阅读的示例项目感到非常困惑、如上所述。
感谢您的任何建议。