请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TDA4VH-Q1 主题中讨论的其他器件:TDA4VH、DRA821、 TDA4VM
工具与软件:
Hardware:TDA4VH 定制板
SDK:ti-processor-sdk-linux-adas-j784s4-evm-09_01_00_06
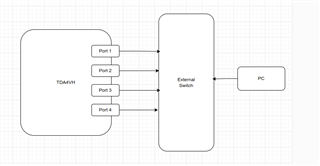
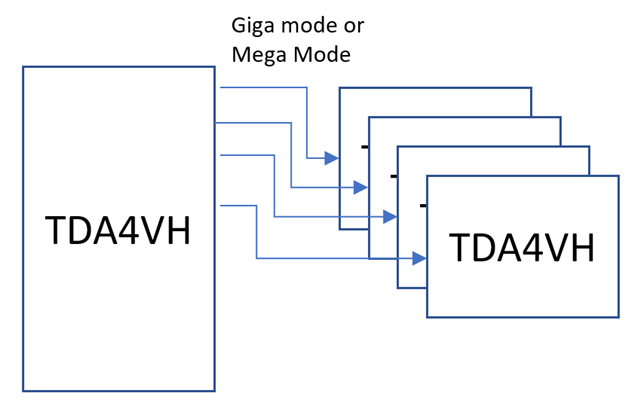
在 SGMII 模式下、8个端口配置为使用8条独立的 SERDES 线
#1。 这些端口使用 iperf3工具单独进行测试。 一台服务器(ifconfig eth1 160.0.0.1 && iperf3 -s)。 一个 client (iperf3 -c 160.0.0.1 -t 120)。
单端口的测试结果:
- 端口速度为93Mb/s (在100Mb/s 全双工模式下)。
- 在以下模式下、端口速度为943Mb/s:1000Mb/s 全双工。
通信吞吐量符合预期。
#2。 同时测试多个端口、带宽率大幅下降、例如、 使用四个主板作为服务器。
(iperf3 -s) 一个客户端(iperf3 -c 160.0.0.1 -t 120 / iperf3 -c 161.0.0.1 -t 120 / iperf3 -c 162.0.0.1 -t 120 / iperf3 -c 163.0.0.1 -t 120)
多个端口同时运行的测试结果:
- 端口速度为46Mb/s (100Mb/s 全双工模式下)。
- 端口速度为303Mb/s (在1000Mb/s 全双工模式下)。 4个端口的总吞吐量= eth2 + eth3 +eth4 +eth5 = 304 + 304 + 307 + 304 =1219Mb/s
尽管使用了单独的 SRDES 线、但它通过测试结果相互影响。
当同时使用多个端口时、每个端口能否达到1Gbps。 提高吞吐量。