

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TDA4VE-Q1 工具与软件:
您好:
SDK:TDA4 VM SDK 10_01_00_04
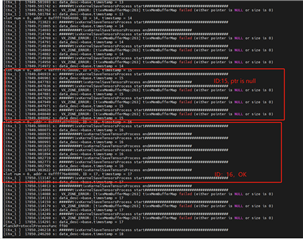
图形节点示例: Input→Scale→pre_proc→TIDL→后处理
1. 非管道模式 、此过程可确保每个帧都产生正确的结果。
2. 流水线模式 、出现异常问题 TIDL 节点每隔一帧返回一个空指针 .
因此、最终输出将在之间交替 一个正确帧和一个异常帧 .
此问题的原因可能是什么?可采取哪些解决方案?
谢谢



