请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TDA4VM-Q1 工具/软件:
您好:
这个问题跟以下这个:(+) TDA4VE-Q1:TDA4 VM SDK 10_01_00_04:TIDL 节点在流水线模式下异常。 -处理器论坛-处理器- TI E2E 支持论坛
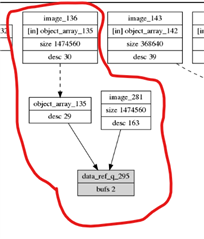
1. 这是我们的图形设计图

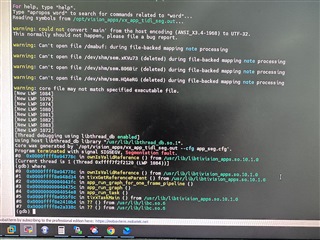
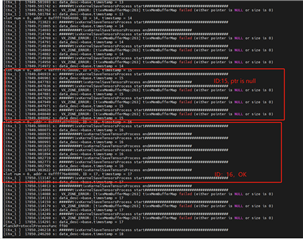
2.在 save_tensor 节点中、我们添加了日志记录、发现 TIDL 节点每隔一帧交替输出一个空指针和正常数据。 因此、我们已经确认 TIDL 输出在这两个输出之间交替 一个正确的帧和一个异常帧 。
3.演示。
在上周的会议中、我们被建议参考 SDK 10.1演示代码 响应。
我们比较了 SDK 8.4和 SDK 10.1中的演示代码:
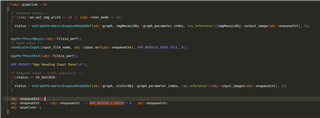
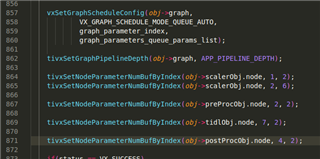
psdkra/vision_apps/apps/dl_demos/app_tidl_seg。 代码是相同的、在应用程序级别没有差异。 如果 SDK 10.1有更新的演示、您能提供一个副本供我们比较吗? 此致、
XJC













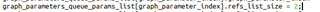 的.refs_list_size
的.refs_list_size