请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM6442 主题: SysConfig 中讨论的其他器件
工具/软件:
大家好:
我与您联系是因为我注意到系统中存在性能问题。
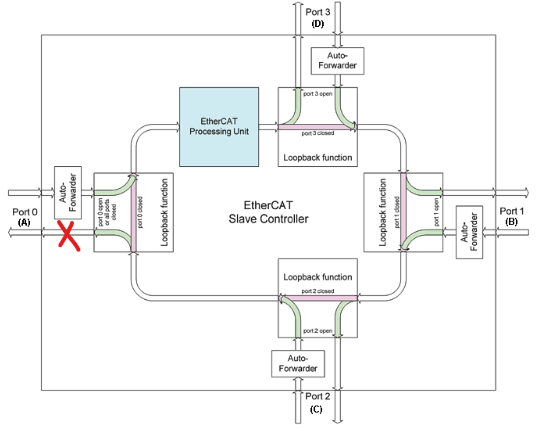
我使用 AM6642 EVM 卡来提供一些背景信息、以便与从网络建立 EtherCAT 通信。
μs 系统的性能非常关键、周期时间大约为100 μ s。 我们必须优化一切、以便一切尽可能快地完成。
因此、我们的应用使用 DMA 和 PRU 与以太网 PHY 连接、从而发送 EtherCAT 帧。
我的问题如下:帧到达 AM6442的 PHY 与帧在我们的应用中实际可用之间的时间间隔异常长(800字节帧需要15 μs)。
我本以为这段时间会短得多、约为2 3 μs。 我们的应用在 R5F-cortex (MAIN_Cortex_R5_0_0)上运行。
如果我理解正确、该帧到达以太网端口、PRU 会实时处理该帧(因此我们希望所需的时间很短)、然后将该帧提供给 DMA、从而将其置于所需的存储器空间(在 MSRAM 中的应用中)。
根据我的理解、DMA 得到了很好的使用、我们在 SysConfig 中按如下方式配置 PRU: 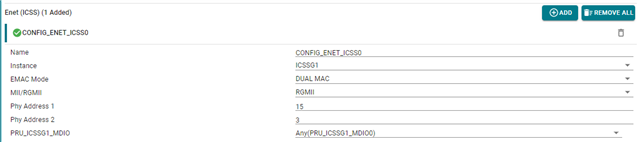

我知道没有提供太多信息、但我不知道该提供什么信息。
你知道我该如何缩短这段时间吗? 是否可以显著降低? 您是否知道这可能需要多长时间?
如果您需要信息、请随时告诉我。
非常感谢您的帮助。
马克西姆