请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:SK-AM68 Thread 中讨论的其他器件:AM68、AM68A
工具/软件:
我使用 AM68 SDK10.0、
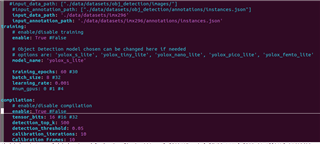
使用 edgeai-modelmaker 进行编译有时会失败并显示以下错误消息:
2025/05/16 14:29:04 - mmengine - error -/home/edgeai-tensorlab/edgeai-mmdetection/mmdet/evaluation/metrics/coco_metric.py - computer_metrics - 465 -整个数据集的测试结果为空。
我的数据集通过 edgeai-composer 导出、同一个数据集通过 modelcomposer 成功编译
我的一些数据集可以编译、有些数据集无法编译。 它是否与数据集中的图像分辨率和数量有关? 为什么会出现上述错误?