请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:DRA821U 工具/软件:
您好的团队、
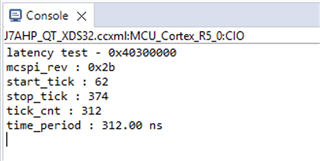
客户发现、写入 器件寄存器(例如 GPIO 输出值变化或配置 MCSPI 需要很长时间、几乎1us。 对于如此强大的芯片、这种性能似乎非常低。
关于这方面的几个问题:
-他们会做什么错误,导致这种行为?
-这是一个正确的解决方案,以增加 CBASS 时钟?
- 他们尝试使用第5.4.5.7.4段(DRA821U TRM 修订版)中介绍的程序在 u-boot 中实现此目的 D)、但对 PLLDIV1和 PLLDIV2寄存器的写入无效。 这些选项保留的值为24 (0x8017)和1 (0x8000)。
- 它们能够更改 PLL0_FREQ_CTRL0寄存器的值、但会影响太多其他内容。
欢迎提供有关如何提高绩效的任何建议!
此致、
Luke