请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:PROCESSOR-SDK-J722S 工具/软件:
我想对来自 ti、j721e-csi2rx 驱动程序的“渐进“视频流进行解码。
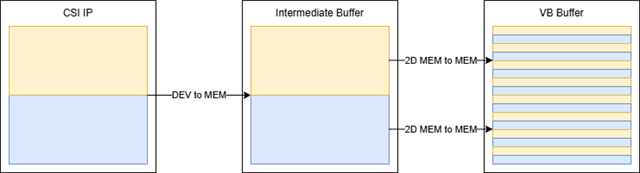
isl7998x 会报告标志 V4L2_FIELD_SEQ_BT 和 V4L2_FIELD_SEQ_TB 、但 TI CSI 驱动程序会将其覆盖为渐进 (V4L2_FIELD_NONE)
这会导致图像有两个副本而不是隔行。
我希望帮助执行以下任一操作:
设置 M2M-deinterlace 设备以解码视频流。
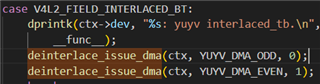
在设置这些标志时、修补 ti、j721e-csi2rx、可能的 ti_csi2rx_start_dma 以发出两个小型交错式 DMA(类似于 M2M-deinterlace)(更新 TI 的驱动程序以支持这两个特定的现场顺序)