Thread 中讨论的其他器件: SK-AM64B、SK-AM62B、 TMDS64EVM
工具/软件:
您好、
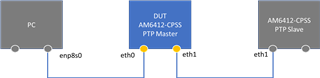
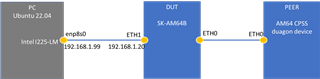
在我们的设计中、我们使用 AM6412 与 DP83867 PHY 配合使用。 我们的产品 有两个以太网接口 eth0 和 eth1。
我们使用的是 6.1.80-rt26 内核版本。
运行 PTP 时的过渡点 eth1 (和已同步)、如果我们更改的链接状态 eth0 PTP 同步开启 eth1 接口将丢失、永远不会恢复。
要恢复同步、我们需要执行以下任何活动
1.重新启动 PTP
2.运行“ifconfig eth1 up“(请注意,它是 eth1、这个接口已经启动并且 PTP 同步工作)
3、打开 Promiscuous 模式“IP link set eth1 promisc on“
进一步调试发现、该问题在某种程度上与 ALE 功能相关。 当 PTP 同步丢失时、我们可以看到随后的两个计数器递增
ALE_DROP: 37378.
RX_PORT_MASK_DROP: 37378.
其他一些观察结果:
1.当另一个接口关闭或打开时,同步丢失(即状态的任何变化)
2.当 PTP 工作时,即使将另一个接口设置为原始状态,同步也不会恢复。
3.此示例显示 PTP 在 eth1 上运行, eth0 状态发生变化,接口发生交叉时,观察到同样的行为。
请在以下日志中查找带有注释的 ptp4l 应用程序
$../ptp4l –2 -P -H -I eth1 -m -q -l 7.
.
. <<<<<<< 输出已剥离
.
ptp4l[17109.394]:端口 1 (eth1):延迟超时
ptp4l[17109.395]:延迟过滤 1316 原始 1330
ptp4l[17110.087]:主偏移 25 s2 频率–26011 路径延迟 1316
ptp4l[17110.394]:端口 1 (eth1):延迟超时
ptp4l[17110.395]:延迟过滤 1316 原始 1310
ptp4l[17111.088]:主偏移 16 s2 频率–26012 路径延迟 1316
ptp4l[17111.395]:端口 1 (eth1):延迟超时
ptp4l[17111.395]:延迟过滤 1312 原始 1311
ptp4l[17111.823]:端口 1 (eth1):收到链路状态通知
[17111.824549] am65-cpsw-Nuss 8000000.Ethernet eth0) <<< eth0 状态在此更改、请注意 PTP 在 eth1 上运行。
[17111.824577] am65-cpsw-Nuss 8000000.Ethernet eth0:配置 phy/rgmii-rxid 链路模式
[17111.833218] 8021q:将 VLAN 0 添加到设备 eth0 上的硬件过滤器中
ptp4l[17112.395]:端口 1 (eth1):延迟超时
ptp4l[17113.395]:端口 1 (eth1):延迟超时
ptp4l[17114.396]:端口 1 (eth1):延迟超时
ptp4l[17114.877]:端口 1 (eth1):收到链路状态通知[17114.879496] am65-cpsw-Nuss 8000000.Ethernet eth0f
亮起
ptp4l[17115.396]:端口 1 (eth1):延迟超时
ptp4l[17116.396]:端口 1 (eth1):延迟超时
ptp4l[17117.396]:端口 1 (eth1):延迟超时
ptp4l[17117.454]:端口 1 (eth1):通知超时 <<< PTP 同步因多播数据包被接口丢弃而丢失
ptp4l[17117.454]:端口 1 (eth1):侦听 announce_receive_timeout_expires 的从设备
ptp4l[17117.454]:已选择本地时钟 543b30.FFFE.0118ef 作为最佳主时钟
ptp4l[17118.454]:端口 1 (eth1):延迟超时
ptp4l[17119.454]:端口 1 (eth1):延迟超时
ptp4l[17120.455]:端口 1 (eth1):延迟超时
ptp4l[17121.455]:端口 1 (eth1):延迟超时
ptp4l[17122.455]:端口 1 (eth1):延迟超时
ptp4l[17123.456]:端口 1 (eth1):延迟超时
ptp4l[17124.249]:端口 1 (eth1):通知超时
ptp4l[17124.456]:端口 1 (eth1):延迟超时
ptp4l[17125.456]:端口 1 (eth1):延迟超时
ptp4l[17126.456]:端口 1 (eth1):延迟超时
ptp4l[17127.457]:端口 1 (eth1):延迟超时
ptp4l[17128.457]:端口 1 (eth1):延迟超时
.
. <<<<<<< 输出已剥离
.
ptp4l[5620.609]:端口 1 (eth1):主器件同步超时
ptp4l[5620.845]:端口 1 (eth1):延迟超时
[5621.584634]设备 eth1 进入混杂模式 <<<eth1 进入混杂模式
ptp4l[5621.586]:端口 1 (eth1):忽略消息
ptp4l[5621.609]:端口 1 (eth1):主器件同步超时
ptp4l[5621.610]:端口 1 (eth1):主器件 TX 通知超时
ptp4l[5621.846]:端口 1 (eth1):延迟超时
ptp4l[5621.846]:延迟滤波 1295 原始 1306
ptp4l[5622.610]:端口 1 (eth1):主同步超时
ptp4l[5622.846]:端口 1 (eth1):延迟超时
ptp4l[5622.847]:延迟滤波 1299 RAW 1304
ptp4l[5623.610]:端口 1 (eth1):主器件同步超时
ptp4l[5623.611]:端口 1 (eth1):主器件 TX 通知超时
ptp4l[5623.846]:端口 1 (eth1):延迟超时
ptp4l[5623.847]:延迟过滤 1304 原始 1312
ptp4l[5624.610]:端口 1 (eth1):主器件同步超时
ptp4l[5624.664]:选定的最佳主时钟 40a6b7.FFFE.9c2706 <<< PTP 再次同步