请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM6442工具/软件:
您好:
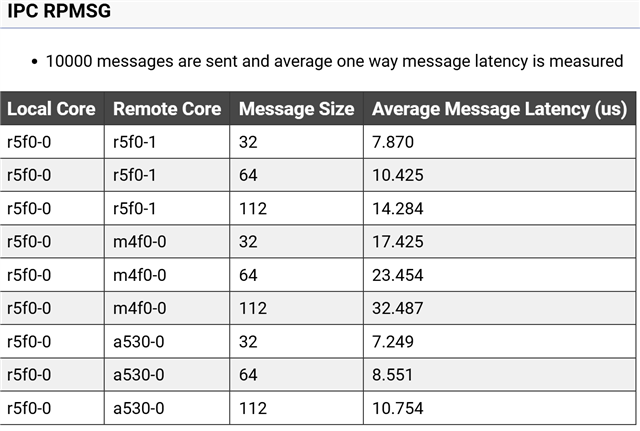
“在我当前针对 AM6442 芯片的项目 (SDK 版本 09_02_00_50) 中、我使用该 ipc_rpmsg 协议对 A53(裸机)和 R5F_0(裸机)内核之间的 IPC 通信进行了测试。 该要求要求必须在其中完成数据传输 每次传输 1ms 。 初始测试结果显示延迟 2 3 μs ,但我观察到突然的尖峰达到 348、000 μs (348ms) 。 我需要验证:
- 这些测量结果是否准确
- 以确保 IPC 机制能够可靠地满足 1ms 要求
- 如果架构不符合此要求、我是否应该重新考虑架构。“