工具/软件:
大家好、我遇到了编译器如何生成.asm 文件的问题。 目前、我使用了一些简单的代码片段 c7x 代码。 我的代码包括一些 for 循环。 当我使用 C7x_code_samples 构建此文件并生成.asm 时。 我不知道我的代码在哪里被转换为 ASM?
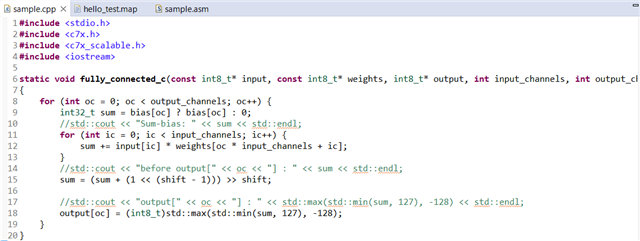
这里是我的代码片段:(如果代码是如此的漫不经心阅读,请随时告诉我,我可以发送一些图像给你们)
静态 void full_connected_c (
const int8_t*输入、
const int8_t*权重、
int8_t*输出、
INT INPUT_CHANNES、
INT OUTPUT_CHANNES、
int32_t 偏置[]、
int32_t 移位)
{
对于 (int oc = 0;oc < output_channels;oc++){
int32_t sum = bias[oc]? 偏差[oc]:0;
//std::cout <<“Sum-bias:“<< sum << std::endl;
对于 (int ic = 0;ic < input_channels;ic++){
SUM +=输入[IC]*权重[oc * INPUT_CHANNES + IC];
}
//std::cout <<“输出前[“<< oc <<“]:“<<总和<< std::endl;
SUM =(SUM +(1 <<(SHIFT - 1)))>> SHIFT;
std::cout <<“output["<<“<< oc <<“]:“<< std::max (std::min (sum、127)、–128)<< std:::endl;
Output[oc]=(int8_t) std::max (std::min (sum、127)、–128);
}
}
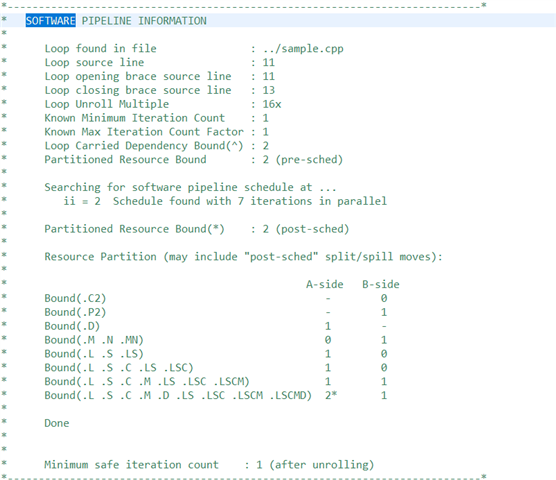
因此在.asm 文件中、im tryin 找出指令集的 full_connected_c 函数实现的位置。 (我以上所做的一切都是为了了解编译器如何处理循环展开因子)
还有一件事、如果你们有任何关于编译阶段、调试等的文档、那就好了。
Tks、
Khoi