工具/软件:
我目前正在使用适用于 SK-AM62A-LP 的 SDK 10.1。 我正在尝试使用 edgeai-tensorlab 中的 r10.1 分支来训练和编译 yolox-nano-lite 模型。 我的数据集遵循标准的 COCO 格式。 我尝试了两种相同的方法-
1.使用 edgeai-mmdetection 进行模型训练、使用 edgeai-benchmark 进行模型编译。 我将经过训练的 Pytorch 权重转换为 ONNX、然后编译它生成工件以进行推理。
2.将 edgeai-modelmaker 的 config-detection.yaml 与 run_modelmaker.py 脚本配合使用 、以 COCO 格式存储在我的数据集上。
对于第一种使用 edgeai-mmdetection 的方法、我可以使用 tools/train.py 获取经过训练的模型以及相应的 ONNX 和 proto 文件。 我参考了 edgeai-benchmark 中提到的用于编译模型的教程、但 在编译模型后得到 map = 0。 我保持 tensor_bits = 32、因此无需校准、我们可以直接编译模型。
e2e.ti.com/.../edgai_5F00_benchmark_5F00_compilation_5F00_run.log
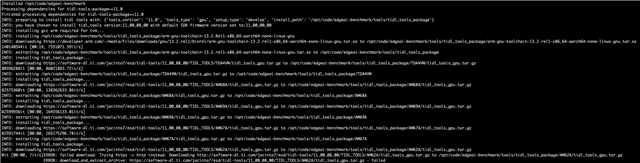
在第二种方法中、我使用了 edgeai-modelmaker 并修改了默认的 config_detection.yaml 以使用我的 COCO 格式数据集。 在这种情况下、编译完成时会出现错误、例如“Invalid Layer Name /multi_level_conv_cls.0/Conv_output_0“。 附加相同的编译日志-
e2e.ti.com/.../modelmaler_5F00_compilation_5F00_run.log
我已经验证我能够从 ONNX 格式的模型中获得预测、并且它的地图不是零。 但是、在尝试编译模型以在 SK-AM62A-LP SOC 上进行推理时、我遇到了上述问题。 我上传了我认为传达此问题所需的日志。 是否需要任何附加文件进行调试?请告诉我。 请提出潜在问题和解决方案。
谢谢你