请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号: TDA4VEN-Q1
尊敬的 TI 专家:
希望这封电子邮件对您有帮助。
我们目前正在开发一个需要在现有图像/视频流之上添加复杂图形渲染(如绘制复杂形状和复杂图标)的项目。
我们建议的架构:
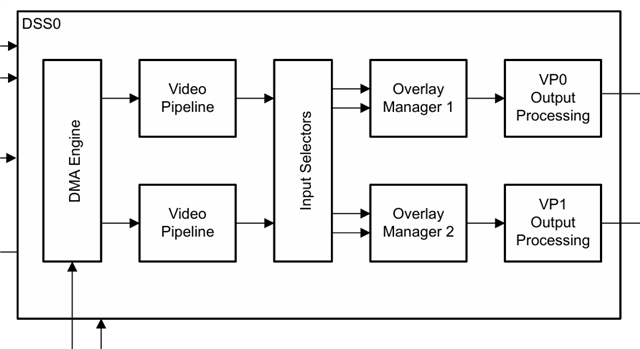
为了实现这一点、我们考虑了 基于 LVGL 的解决方案 。 其概念是让 LVGL 将 UI 数据渲染到专用图形层上、而原始视频流占用另一层。 在显示阶段、我们打算利用 DSS(显示子系统)硬件 对这些层执行硬件覆盖/混合以输出最终映像。
架构困境:
但是、我们面临着架构瓶颈。 当前、display node 在上运行 MCU2_0(主 R5F) 核心、而 LVGL 缺乏对的原生适应 VID2 API 和 DSS 驱动器。
为了解决此问题、我们进行了头脑风暴、讨论了两个潜在的数据流路径、但这两个路径都有各自的权衡:
- 路径 A(A 芯直接显示): 我们
display node在上开发了一个运行的定制器件 A 型磁芯 。 LVGL 将利用标准 Linux DRM 框架直接推送显示、完全绕过基于display node主 R5F 的现有 FVID2。 - 路径 B(A 内核渲染+ R5F 覆盖): LVGL 在 A 内核上呈现 UI 缓冲区、然后将此呈现缓冲区传递到主 R5F(可能通过 IPC/共享存储器)。
display node然后、主 R5F 上的将获取原始视频缓冲区和 UI 缓冲区、调用 DSS 驱动程序(通过 FVID2)以执行最终的硬件叠加。
在此背景下、我们非常感谢您对以下两个问题的见解和建议:
-
关于 R5F DSS 驱动程序功能: 主 R5F 上的当前 DSS 驱动程序实现(通过 FVID2 API)是否完全支持多层硬件覆盖/混合? 具体而言、它是否可以同时管理和混合专用视频平面和单独的 UI 图形平面(理想情况下支持 α 混合)?
- 关于 LVGL 适应: 是否有更巧妙或更高效的实现策略来使 LVGL 适应我们的当前架构而不完全绕过 R5F 显示节点?
- 关于替代解决方案: 如果我们要远离 LVGL、您是否会推荐其他渲染框架或软件解决方案来处理这种复杂的图形叠加?
感谢您的时间和专业知识。 期待您的见解与反馈。
此致、