请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM6442 我正在为 PRU-ICSS 器件(AM335x、AM437x、AM57x)、PRU-SS 器件(AM62x)或 PRU_ICSSG 器件(AM24x、AM64x、AM65x)编写 PRU 应用。 我想计算读取或写入需要多少个时钟周期。 我该怎么做?
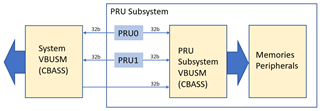
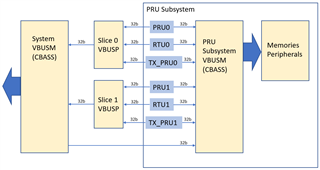
此常见问题解答是 PRU 阅读延迟应用手册的扩展。 稍后将使用此常见问题解答中的信息更新应用手册。
我正在为 PRU-ICSS 器件(AM335x、AM437x、AM57x)、PRU-SS 器件(AM62x)或 PRU_ICSSG 器件(AM24x、AM64x、AM65x)编写 PRU 应用。 我想计算读取或写入需要多少个时钟周期。 我该怎么做?
此常见问题解答是 PRU 阅读延迟应用手册的扩展。 稍后将使用此常见问题解答中的信息更新应用手册。