主题中讨论的其他器件:TMDSEVM572X
您好、香榭丽舍
硬件: TMDSEVM572X
,:Processor SDK Linux 06_03_00_106 μ s
机器学习:TIDL Caffe-Jacinto。
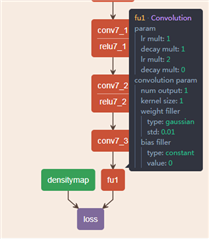
客户使用 Caffe-Jacinto 来训练网络,将最后一层卷积 内核定义为1*1,输出为1。 但在训练时、它会提示错误消息。 
TI 示例中有类似的结构、不同之处在于输出是不同的
什么是 Wong?
, ,,MobileNet conv3_1/SEP 和 conv3_2/SEP 都是内核1*1组为1 μ A、但输出通道不匹配组。 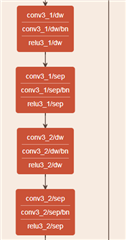
客户的网络配置。
第{
名称:"FU1_1/dw"
类型:"卷积"
底部:"conv7_3"
顶部:"FU1_1/dw"
卷积_param{
num_output:64
BIAS_TERM:false
焊盘:1.
kernel_size:3.
组:64
跨度:1.
weight_ciller{
类型:"MSRA"
}
稀释:1.
}
}
第{
名称:"FU1_1/dw/bn"
类型:"BatchNorm"
底部:"FU1_1/dw"
顶部:"FU1_1/dw"
batch_norm_param{
SCALL_BIAS:true
}
}
第{
名称:"relu1_1/dw"
类型:"Relu"
底部:"FU1_1/dw"
顶部:"FU1_1/dw"
}
第{
名称:"FU1_1/SEP"
类型:"卷积"
底部:"FU1_1/dw"
顶部:"FU1_1/SEP"
卷积_param{
num_output:64
BIAS_TERM:false
焊盘:0
kernel_size:1.
组:1.
跨度:1.
weight_ciller{
类型:"MSRA"
}
稀释:1.
}
}
第{
名称:"FU1_1/SEL/bn"
类型:"BatchNorm"
底部:"FU1_1/SEP"
顶部:"FU1_1/SEP"
batch_norm_param{
SCALL_BIAS:true
}
}
第{
名称:"relu1_1/SEP"
类型:"Relu"
底部:"FU1_1/SEP"
顶部:"FU1_1/SEP"
}
第{
名称:"FU1_2/dw"
类型:"卷积"
底部:"FU1_1/SEP"
顶部:"FU1_2/dw"
卷积_param{
num_output:64
BIAS_TERM:false
焊盘:1.
kernel_size:3.
组:64
跨度:1.
weight_ciller{
类型:"MSRA"
}
稀释:1.
}
}
第{
名称:"FU1_2/dw/bn"
类型:"BatchNorm"
底部:"FU1_2/dw"
顶部:"FU1_2/dw"
batch_norm_param{
SCALL_BIAS:true
}
}
第{
名称:"relu1_2/dw"
类型:"Relu"
底部:"FU1_2/dw"
顶部:"FU1_2/dw"
}
第{
名称:"FU1_2/SEP"
类型:"卷积"
底部:"FU1_2/dw"
顶部:"estdmap"
卷积_param{
num_output:1.
BIAS_TERM:false
焊盘:0
kernel_size:1.
组:1.
跨度:1.
weight_ciller{
类型:"MSRA"
}
稀释:1.
}
}
客户的网络结构 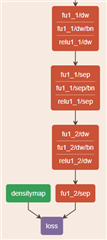
谢谢。
Rgds
闪亮