请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
https://e2e.ti.com/support/processors-group/processors/f/processors-forum/992238/tda4vm-c7x-training
器件型号:TDA4VM主题中讨论的其他器件:PROCESSOR-SDK-J721E
您好!
我下载了版本0.5的 C7x 培训,该培训来自 PROCESSOR-SDK-J721E v6.1页面: PROCESSOR-SDK-RTOS-J721E_06.01.01.12 | TI.com
此培训的新版本是否可用或已计划? 如果有计划、您能否提供大致的供货日期?
在此新版本中、高级示例是否包含其文档?
现在是否可以获得这些示例的文档、即使尚未完成也是如此?
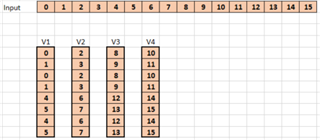
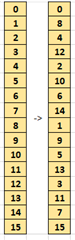
FFT 示例(c7x_fft1d_16bit)对我有很大的兴趣、但没有文档甚至评论。
非常感谢、
克莱蒙特