Other Parts Discussed in Thread: MATHLIB
您好!
首先、我要感谢 TI 为客户提供的所有文档和示例。 我们还发现论坛在大多数时候都非常有用。
我们将在 TMS32C6748上开发用于实时应用的项目。 我们遇到了中断延迟问题、我们找不到明显的原因/解决方案。
首先,让我简要介绍 一下系统的设计和实施:
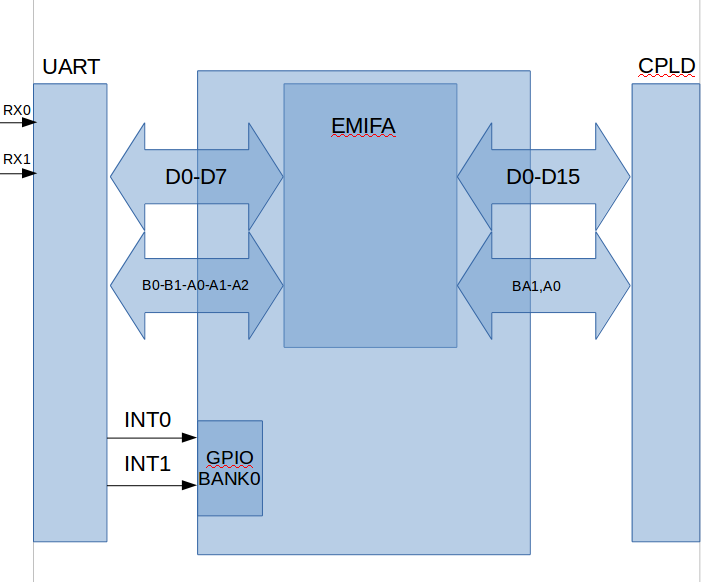
DSP 连接到一个5兆波特双通道 UART ( 64字节 FIFO、可编程触发电平、多个状态/配置寄存器)
通过 EMIFA (根据 UART 芯片的数据表、48Mhz 速度、CS4存储器空间、异步、8位模式和时序)
此外,还连接到 GPIO 组0 (1和2)的2条中断线路。
功能设计:
每毫秒、DSP 接收的每通道总字节为192字节、分为3个64字节的数据包(FIFO 最大容量)、这需要180微秒、间隔为100微秒(以便 CPU 有时间为中断提供服务)
为了简单起见、让我们将从两个通道接收到的字节称为"数据样本"。
DSP 应该在2080个样本上运行一个算法、该算法除其他外、使用了 DSPLIB、MathLib。
实施:
为了最大限度地利用 CPU、中断服务由 ISR 完成、以检查状态寄存器、 随后将触发手动 EDMA3事件、以将传入的数据缓冲成乒乓式方式、并将其馈送到应在主程序中运行的算法中。
我们通过 Code Composer 7、XDS100v3和 C6748 Starterware 1.2.4以456Mhz 频率运行该板。 代码链接为在启用 L2缓存的情况下从 DDR2运行。
结果:
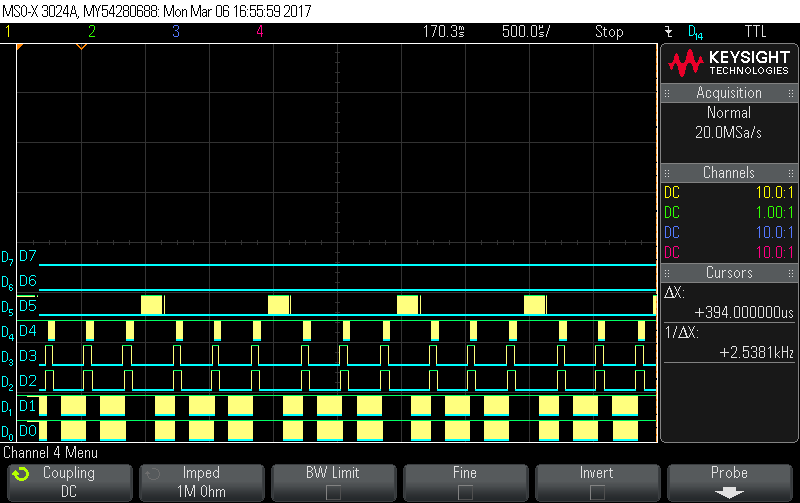
在每个64字节块之后、中断线路变为高电平、然后 CS4开始切换、这说明了 ISR 处理和 EDMA3读取。 它们都可以正常工作、并为我们提供预期结果。 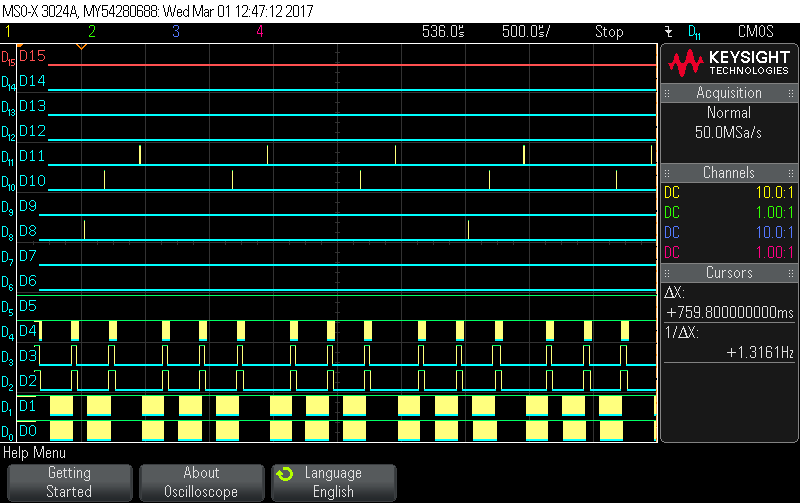
D0:UART 通道0传入数据
D1:UART 通道1传入数据
D2:UART 通道0中断线
D3:UART 通道1中断线
D4:EMIFA CS4
问题:
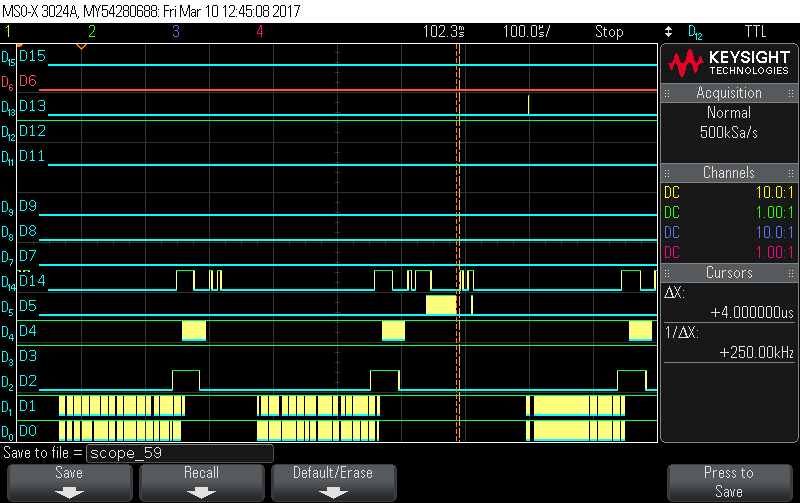
当我们开始将缓冲区馈送到算法时会发生这种情况、而我们将2080个样本缓冲到"PingBuffer"(大小为1MB)中、然后将其传递给在主循环中运行的算法。 我们开始填写"Pong buffer"。 一切都在正常运行直到某个时间点、ISR 会异常延迟、我们会失去同步、因此我们无法满足最后期限。
以下快照说明了此行为。 
我们通读了论坛和我们可用的大多数手册,并为此提出了多种可能的原因:
首先、编译器可以禁用中断。 我们重新编译了使用的所有代码、从我们的开始、到 C 标准库、Mathlib 和 DSP 库、其中-interrupt_treshold = 1。 我们研究了汇编输出、从未使用"DINT"指令(mathlib 中的某些汇编文件除外、我们尝试对其注释 DINT 或重新实现 C 中使用的函数。)
第二、我们研究了 mDDR/DDR2控制器的总线争用。 由于 GEL 文件正在为我们执行初始化、PBBPR 的默认值为0x20、我们将其降至0x10、而不会对问题产生任何影响。
第三、由于 CPU 不允许在硬件中嵌套中断、因此我们确保仅对 UART 中断进行编程(仅用于测试目的)
最后、主外设寄存器的当前配置为使用的 DMA 控制器提供了更高的优先级(默认配置和所需配置)、为 CPU 提供更高的优先级不会改变这个延迟中的任何内容。
既然我们已经尝试了所有这些,我们就开始怀疑这是一个缓存问题。 L1P 中的高速缓存缺失是否会导致此长延迟? 如果是、我们可以对此采取什么措施?
编辑:我们尝试将算法文本部分链接到 DDR2,其余部分都链接到 L2RAM 空间,结果相同。
我们还愿意接受任何建议、以帮助我们解决问题。
提前感谢您。
此致、