请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
https://e2e.ti.com/support/processors-group/processors/f/processors-forum/1165701/tda4vm-tda4vm
器件型号:TDA4VM您好!
我在考虑 QAT 时有一个问题。
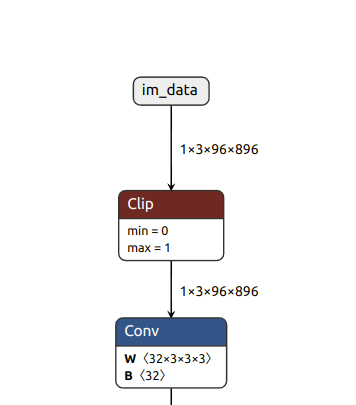
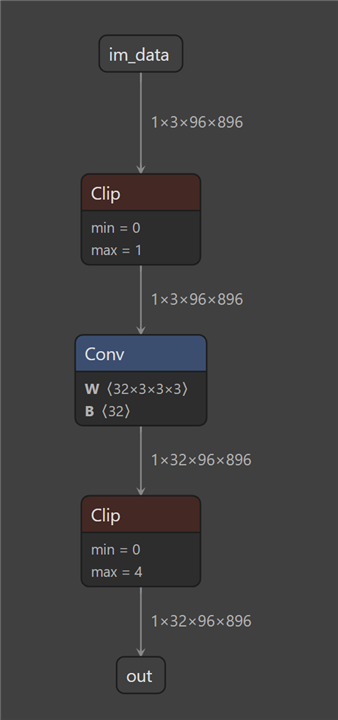
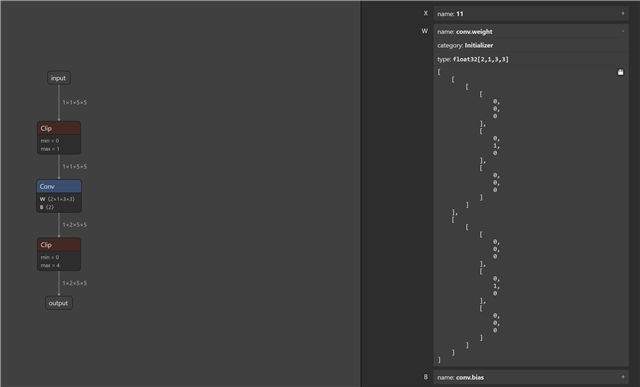
我想对一些模型层执行8位量化、并以16位精度推理一些层。 我对电桥-电感器进行了一些更改、以便这些层(卷积)不会被替换
对于 QuantTrainConv2d、它们也不会接收 PACT2。 这些图层不会在 ONNX 图中"接收"剪辑图层。
现在、我想在 TIDL 中执行编译并创建伪影。 我不想更改已计算的8位图层的剪辑范围。 但是、我想为16位范围的"非触控"计算这些值。 如何做到这一点?
谢谢、
Alex。


 '
'