

您好!
根据代码的执行次数、GPMC 读取访问会受到影响。
GPMC 寄存器设置如下。
GPMC_CONFIG1_I 0x60 0x00601211
GPMC_CONFIG2_I 0x64 0x00090902
GPMC_CONFIG3_I 0x68 0x00010100
GPMC_CONFIG4_I 0x6C 0x06030903
GPMC_CONFIG5_I 0x70 0x00090A0A
GPMC_CONFIG6_I 0x74 0x86020281
GPMC_CONFIG7_I 0x78 0x00000F42
在 GPMC 读取访问期间、
当 CortexA15执行40多条指令时、GPMC 访问会产生170ns 的延迟。
为什么会发生这种延迟?
请告诉我如何解决延迟问题。
①call _16_READ:
call_16_read:
ldrh R10、[r0]/* r0 = GMPC LSC0上的地址*/
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
BX LR
GPMC 读取之间无指令->无延迟
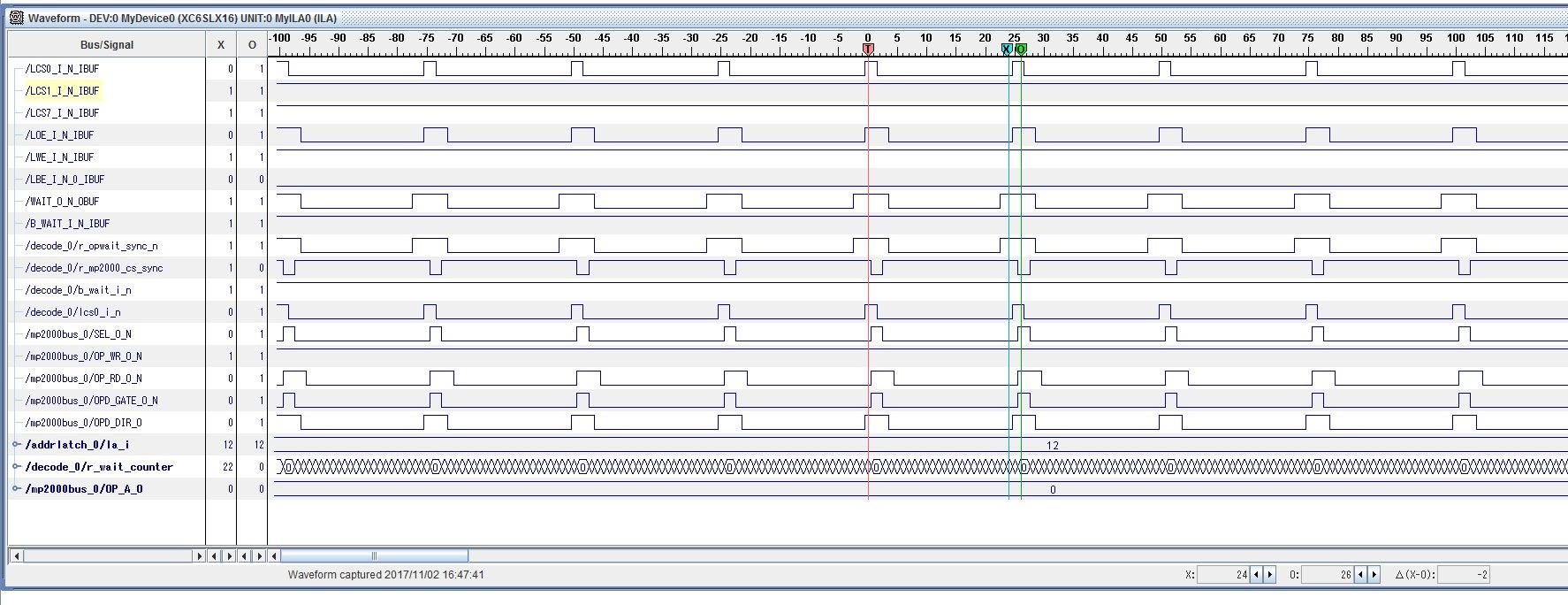
②call _16_read20:
ldrh R10、[r0]/* r0 = GMPC LSC0上的地址*/
ldrh R9、[R1]/* R1 =堆栈上的地址(将以 cach 为单位)*/
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R10、[r0]/* r0 = GMPC LSC0上的地址*/
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
BX LR
在 GPMC 读取之间添加了20行指令->在访问添加的代码之间无延迟
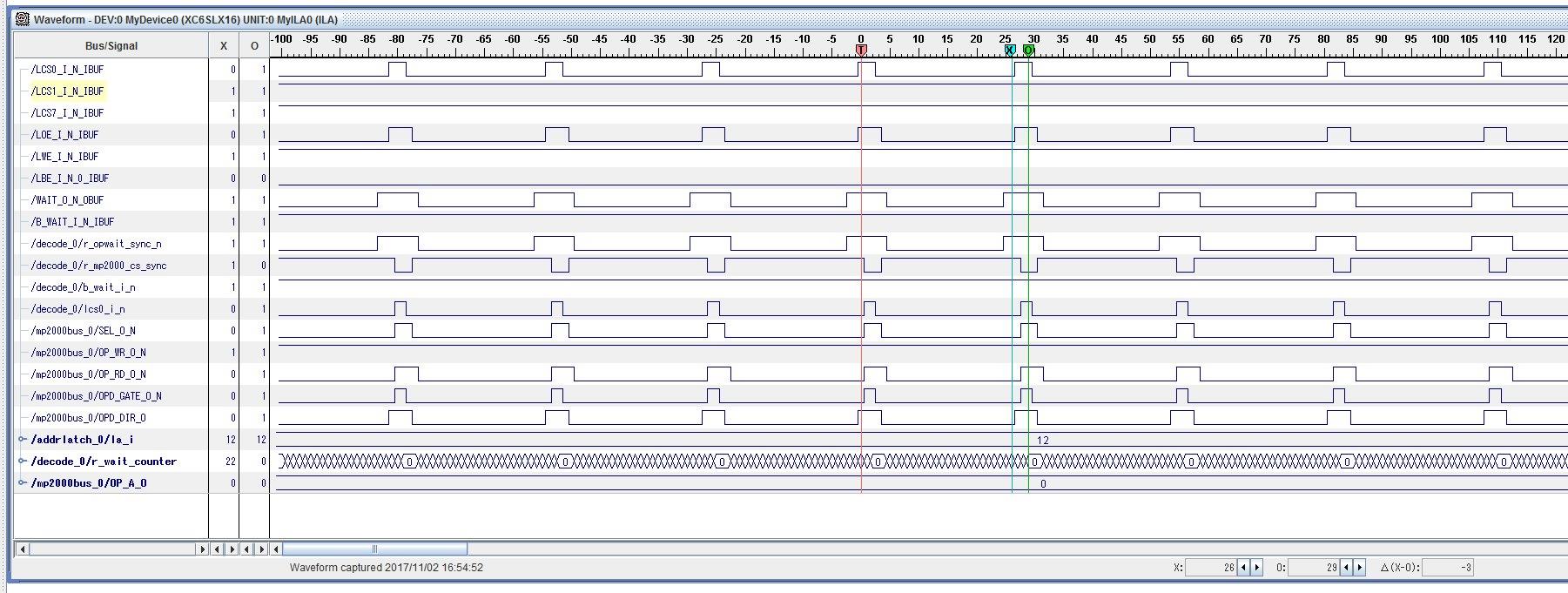
③call _16_read40:
call_16_read40:
ldrh R10、[r0]/* r0 = GMPC LSC0上的地址*/
ldrh R9、[R1]/* R1 =堆栈上的地址(将以 cach 为单位)*/
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R9、[R1]
ldrh R10、[r0]/* r0 = GMPC LSC0上的地址*/
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
ldrh R10、[r0]
BX LR
在 GPMC 读取之间添加了40行指令-在访问添加的代码之间增加了170ns 的延迟
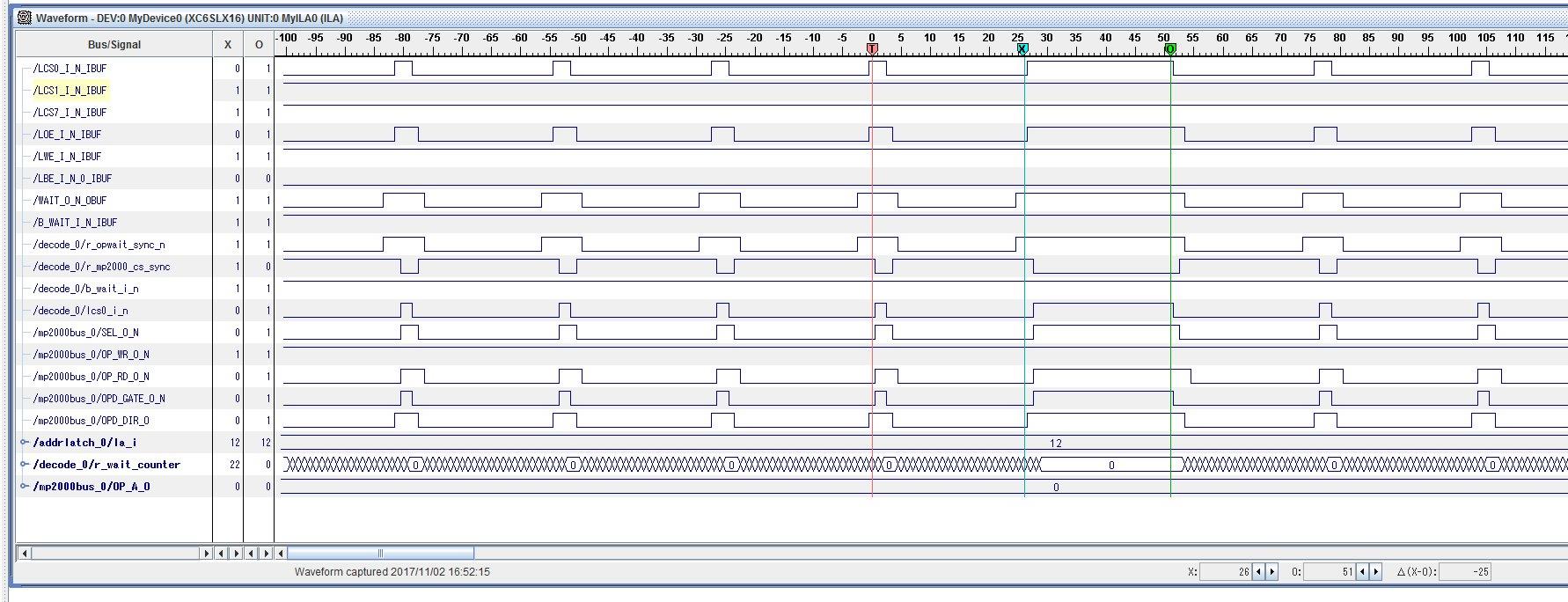
此致、
新义郎
