请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM6442 主题中讨论的其他器件:SK-AM64B、 AM6422、 DRA821U
工具与软件:
尊敬的专家:
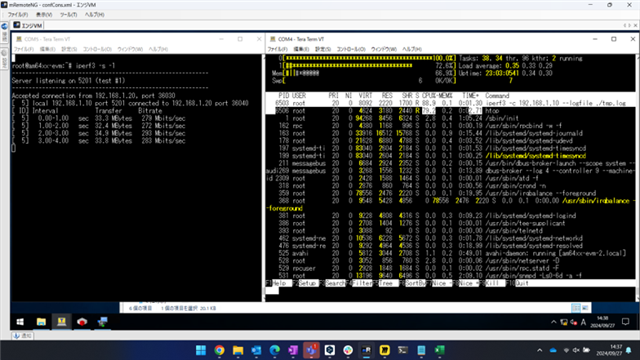
PRP 吞吐量是通过将两个 SK-AM64B 相互连接而测得的。
iperf 客户端-服务器通信的测量吞吐量约为300Mbps。
-主板上的两个以太网端口连接到通信伙伴的端口、中间没有 L2SW。
-在 Linux 驱动程序中实现的 PRP 堆栈用于 PRP 的非卸载模式。
使用的 SDK 为09.02.01.09 (2024年3月29日)。
-在没有 PRP 的普通单电缆连接中,吞吐量超过800Mbps。
那么、这里是我的问题。 请尽可能多地回答。
SK-AM64B 300Mbps 的 PRP 吞吐量是否合理?
1)我使用 PRP 的方式是否有错误?
PRP 支持的接口速度在1Gbps 时是否正确? 还是100Mbps?
我使用的 SDK 中的 PRP 是否实现了 IEC 62439-3第3版标准?
2)如何提高吞吐量?
如果我使用两个 PC-Linux 而非 SK-AM64B、PRP 的吞吐量为1Gbps。
更新到最新 SDK 10.00.07.04 (2024年8月14日)是否会对其进行改进?
有调优项目吗?
3)这是否是非卸载模式下的性能限制?
何时完成 PRU-ICSSG 和 CPSW3g 的 PRP 卸载模块(固件)?
何时将提供用于这些卸载模块的 Linux 驱动程序?
提前感谢您
此致、
大野武志