请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM62P 工具与软件:
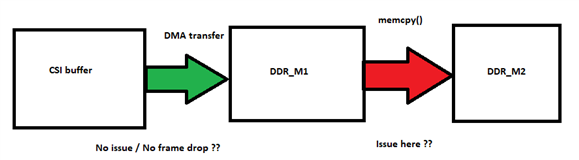
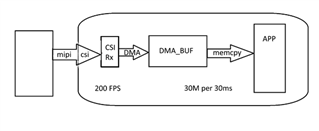
我们使用 v4l2框架在调试 ads6311时捕获图像。 发现将出现帧丢弃。 我们进一步分析发现 memcpy 复制3932160字节、需要大约30ms。 因此、DMA 速率可能太慢。
ti_csi2rx0: ticsi2rx@30102000 {
compatible = "ti,j721e-csi2rx";
dmas = <&main_bcdma_csi 0 0x5000 15>, <&main_bcdma_csi 0 0x5001 15>,
<&main_bcdma_csi 0 0x5002 15>, <&main_bcdma_csi 0 0x5003 15>;
dma-names = "rx0", "rx1", "rx2", "rx3";
reg = <0x00 0x30102000 0x00 0x1000>;
power-domains = <&k3_pds 182 TI_SCI_PD_EXCLUSIVE>;
#address-cells = <2>;
#size-cells = <2>;
ranges;
status = "disabled";
cdns_csi2rx0: csi-bridge@30101000 {
compatible = "cdns,csi2rx";
reg = <0x00 0x30101000 0x00 0x1000>;
clocks = <&k3_clks 182 0>, <&k3_clks 182 3>, <&k3_clks 182 0>,
<&k3_clks 182 0>, <&k3_clks 182 4>, <&k3_clks 182 4>;
clock-names = "sys_clk", "p_clk", "pixel_if0_clk",
"pixel_if1_clk", "pixel_if2_clk", "pixel_if3_clk";
phys = <&dphy0>;
phy-names = "dphy";
power-domains = <&k3_pds 182 TI_SCI_PD_EXCLUSIVE>;
ports {
#address-cells = <1>;
#size-cells = <0>;
csi0_port0: port@0 {
reg = <0>;
status = "disabled";
};
csi0_port1: port@1 {
reg = <1>;
status = "disabled";
};
csi0_port2: port@2 {
reg = <2>;
status = "disabled";
};
csi0_port3: port@3 {
reg = <3>;
status = "disabled";
};
csi0_port4: port@4 {
reg = <4>;
status = "disabled";
};
};
};
};
。将优先级更改为15 μ s
DMA =<&MAIN_Bcdma_CSI 0 0x5000 15>、<&MAIN_Bcdma_CSI 0 0x5001 15>、
<&MAIN_BCDMA_CSI 0 0x5002 15>、<&MAIN_BCDMA_CSI 0 0x5003 15>;
更改后、我们无法捕获数据、数据为0。DMA 可以加速哪种方法。
版本:09.02.01.10
e2e.ti.com/.../vision-tiam62p5-linux6.1.83-memcpy_1780F6654B6DD58B_.txt
请帮助!谢谢!