请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM6442 工具与软件:
从以下 URL 下载了 TI 的 Linux 内核、并使用 Linux 内核的 RT (实时)版本切换到了 ti-rt-linux6.6.6.y-cicd 版本。
https://git.ti.com/cgit/ti-linux-kernel/ti-linux-kernel/
使用 rpmsg_char_simple.c 中的以下示例代码
e2e.ti.com/.../4276.rpmsg_5F00_char_5F00_simple.c
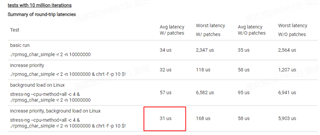
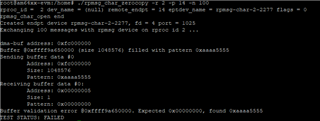
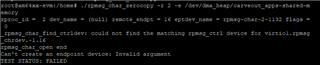
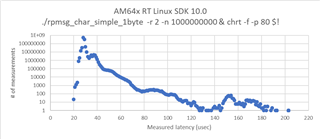
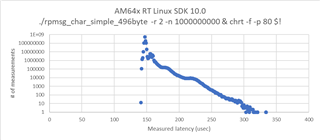
测试了超过100,000次、并使用命令./rpmsg_char_simple -r 2 -n 100000和 chrt -f -p 10 $!设置优先级。 测试结果如下图所示:
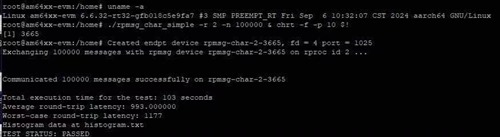
从图中可以看出、最大延迟为1177us、这个值太高了、不符合我们的电流要求。 是否有优化的空间?