请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:PROCESSOR-SDK-AM68A 主题中讨论的其他器件:AM68A
工具与软件:
您好!
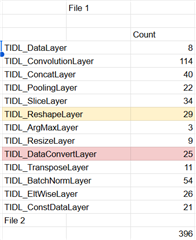
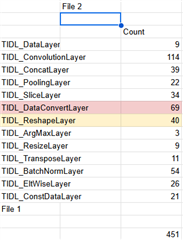
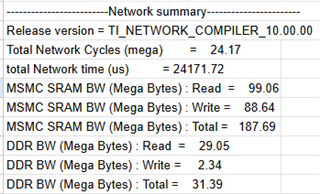
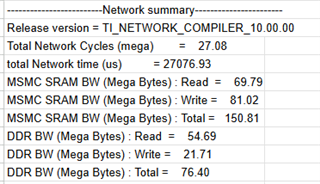
我目前正在使用 TIDL (SDK v10.00.08)在 AM68a 电路板上配置自定义神经网络。 我注意到、在模型工件生成期间、创建了两个 csv 文件(请参阅附带的屏幕截图)、其中 每层的运行时间不同、但存储器占用空间类似。 这两个文件的区别是什么?

工具与软件:
您好!
我目前正在使用 TIDL (SDK v10.00.08)在 AM68a 电路板上配置自定义神经网络。 我注意到、在模型工件生成期间、创建了两个 csv 文件(请参阅附带的屏幕截图)、其中 每层的运行时间不同、但存储器占用空间类似。 这两个文件的区别是什么?