

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TDA4VM 工具与软件:
您好!
由于问题没有解决,我重新发布我的问题: https://e2e.ti.com/support/processors-group/processors/f/processors-forum/1445132/tda4vm-inference-benchmarking-statistics---ddr-bw-per-image
在云或 EVM 上执行推理时、我一直观察到每个图像的 DDR 使用率非常高、而我的同事在两年前报告仅为0MB。
我在云和 EVM 上都尝试过各种模型、总是得到很高的结果。
云上运行
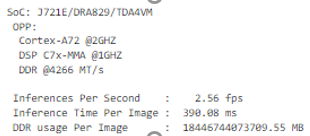
模式
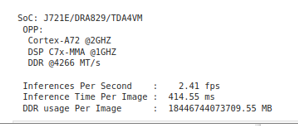
相同型号的旧结果:
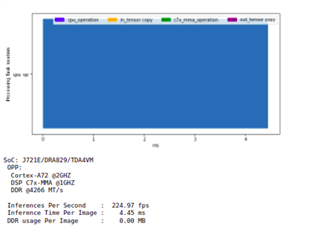
这些结果是否是典型结果、或者 edgeai_tidl_tools 的计算方法尚未更新?
谢谢。此致、
Azer



