请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:PROCESSOR-SDK-J722S 工具与软件:
大家好、团队:
在 TIDL 10.00.08.00中
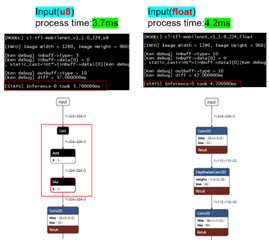
我尝试使用输入= uint8且输入= float 来转换默认模型(mobilenet1v)、
我发现 input=uint8的模型会执行去量化步进、
而其余器件与 input=float 的模型相同。
不过、input=uint8的模型实际上具有更短的推理时间。
我不知道为什么会出现这种症状。
感谢您的帮助。
此致、
Ken