

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM6442 工具与软件:
我们使用 GPMC 总线 在异步模式下并使用 WAIT 信号与 FPGA 进行连接。
发生的奇怪的事情是、当读取时、我们注意到一个周期和下一个周期之间的时间比写入时长得多(大约增加120 ns)。
为了进行测试、我们插入了一个100个读数周期和一个100个文章周期:
static volatile unsigned short n,a,b,c,d,e,f,g,h,i,l;
for (n=0;n<10;n++)
{
a=(* (unsigned short *) 0xA01E000);
b=(* (unsigned short *) 0xA01E002);
c=(* (unsigned short *) 0xA01E004);
d=(* (unsigned short *) 0xA01E006);
e=(* (unsigned short *) 0xA01E008);
f=(* (unsigned short *) 0xA01E00A);
g=(* (unsigned short *) 0xA01E00C);
h=(* (unsigned short *) 0xA01E00E);
i=(* (unsigned short *) 0xA01E010);
l=(* (unsigned short *) 0xA01E012);
}
for (n=0;n<10;n++)
{
(* (unsigned short *) 0xA01C00E)=a;
(* (unsigned short *) 0xA01C010)=b;
(* (unsigned short *) 0xA01C012)=c;
(* (unsigned short *) 0xA01C00E)=d;
(* (unsigned short *) 0xA01C010)=e;
(* (unsigned short *) 0xA01C012)=f;
(* (unsigned short *) 0xA01C00E)=g;
(* (unsigned short *) 0xA01C010)=h;
(* (unsigned short *) 0xA01C012)=i;
(* (unsigned short *) 0xA01C00E)=l;
}
写入时间如下:
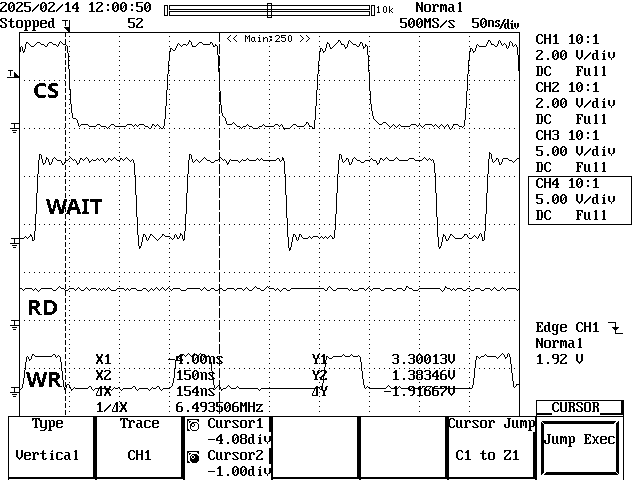
这些是读取时间:
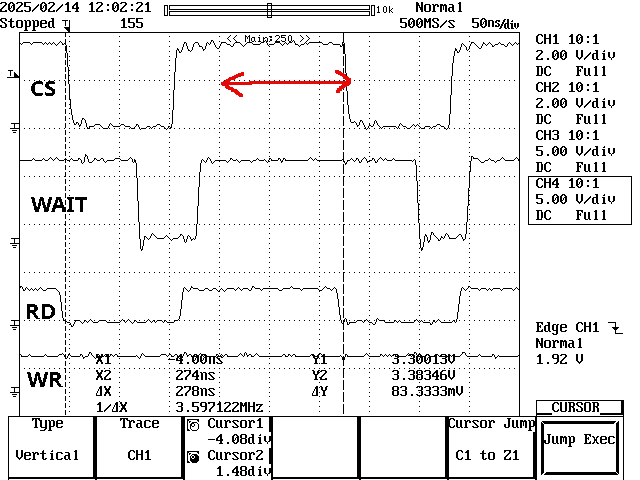
您可以注意到、在读取访问过程中、CS 变为高电平与恢复低电平之间的间隔时间要长得多(红色箭头表示差异)。
显然、当读取时、CPU 必须将变量保存在 DDR 中、但这是一个操作、所需的时间应短得多、不到120ns。
我们几乎将 GPMC 总线时序值设置为最小值、但没有改善。 如果我们进一步减小它们、总线将开始产生错误或锁定 CPU。
以下是我们使用的最低可能设置:
WAIT0 =高电平有效
BUS= 16位
WRACCESSTIME= 2 (15ns)
RDACCESSTIME= 2 (15ns)
WRCYCLETIME= 4 (30ns)
RDCYCLETIME= 4 (30ns)
CSONTIME= 1 (7、5ns)
CSRDOFFTIME= 3 (22ns)
CSEXTRADELAY= 0
WEONTIME= 0
OEONTIME= 0
WEOFFTIME= 4 (30ns)
OEOFFTIME= 4 (30ns)
CYCLE2CYCLEDELAY= 6 (45ns)
BASEADDRESS= x.10
代码:
//******* GPMC INITIALIZATION (FPGA interface)********************
// note: GPMC_FCLK = 133Mhz (1 period = 7.5nsec).
SOC_moduleClockEnable(TISCI_DEV_GPMC0, 1);
// wait for reset (RESETDONE)
while((*((volatile uint32_t*)GPMC_SYSSTATUS) & TESTBIT_0)==0)
{}
//WAIT0 active high, WAIT1 active high
*((volatile uint32_t*)GPMC_CONFIG) = SETBIT_9 | SETBIT_8;
//GPMC IRQ disabled
*((volatile uint32_t*)GPMC_IRQENABLE) = 0;
//TIMEOUTSTARTVALUE=511 GPMC_FCLK cycles, TIMEOUTENABLE=0
*((volatile uint32_t*)GPMC_TIMEOUT_CONTROL) = (511<<4);
//WAIT MONITORING ENABLED (su read e write), uso WAIT0, 16 BIT BUS
*((volatile uint32_t*)GPMC_CONFIG1_0) = SETBIT_22 | SETBIT_21 | SETBIT_12;
//CSWROFFTIME=3 (22ns), CSRDOFFTIME=3 (22ns), CSEXTRADELAY=0, CSONTIME=1
*((volatile uint32_t*)GPMC_CONFIG2_0) = (3<<16) | (3<<8) | 1;
//WEOFFTIME=4 (30ns), WEONTIME=0, OEOFFTIME=4 (30ns), OEONTIME=0
*((volatile uint32_t*)GPMC_CONFIG4_0) = (4<<24) | (4<<8);
//PAGEBURSTACCESSTIME=1(default), RDACCESSTIME=2 (15ns), WRCYCLETIME=4 (30ns) , RDCYCLETIME=4 (30ns)
*((volatile uint32_t*)GPMC_CONFIG5_0) = (1<<24) | (2<<16) | (4<<8) | 4;
//WRACCESSTIME=2 (15ns), WRDATAONADMUXBUS=7(default), CYCLE2CYCLEDELAY=6 (45ns), CYCLE2CYCLESAMECSEN=1
*((volatile uint32_t*)GPMC_CONFIG6_0) = (2<<24) | (7<<16) | (6<<8) | SETBIT_7;
//MASKADDRESS=0xF(16MB), CSVALID=1, BASEADDRESS=0x10 (0x50000000)
*((volatile uint32_t*)GPMC_CONFIG7_0) = (0xF<<8) | SETBIT_6 | 0x10;
//*********************************************************************
那么、最后一个问题是:是否可以缩短一个读取周期和下一个读取周期之间的时间以便使其像写入一样快、或者它是否是 GPMC 总线架构的限制、因此不能加以改进?
提前感谢
此致
Francesco Parolini
