

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:CC2530 ZNP 的串行接口没有响应、由于 IAR 在调试过程中打开、我有更多信息。
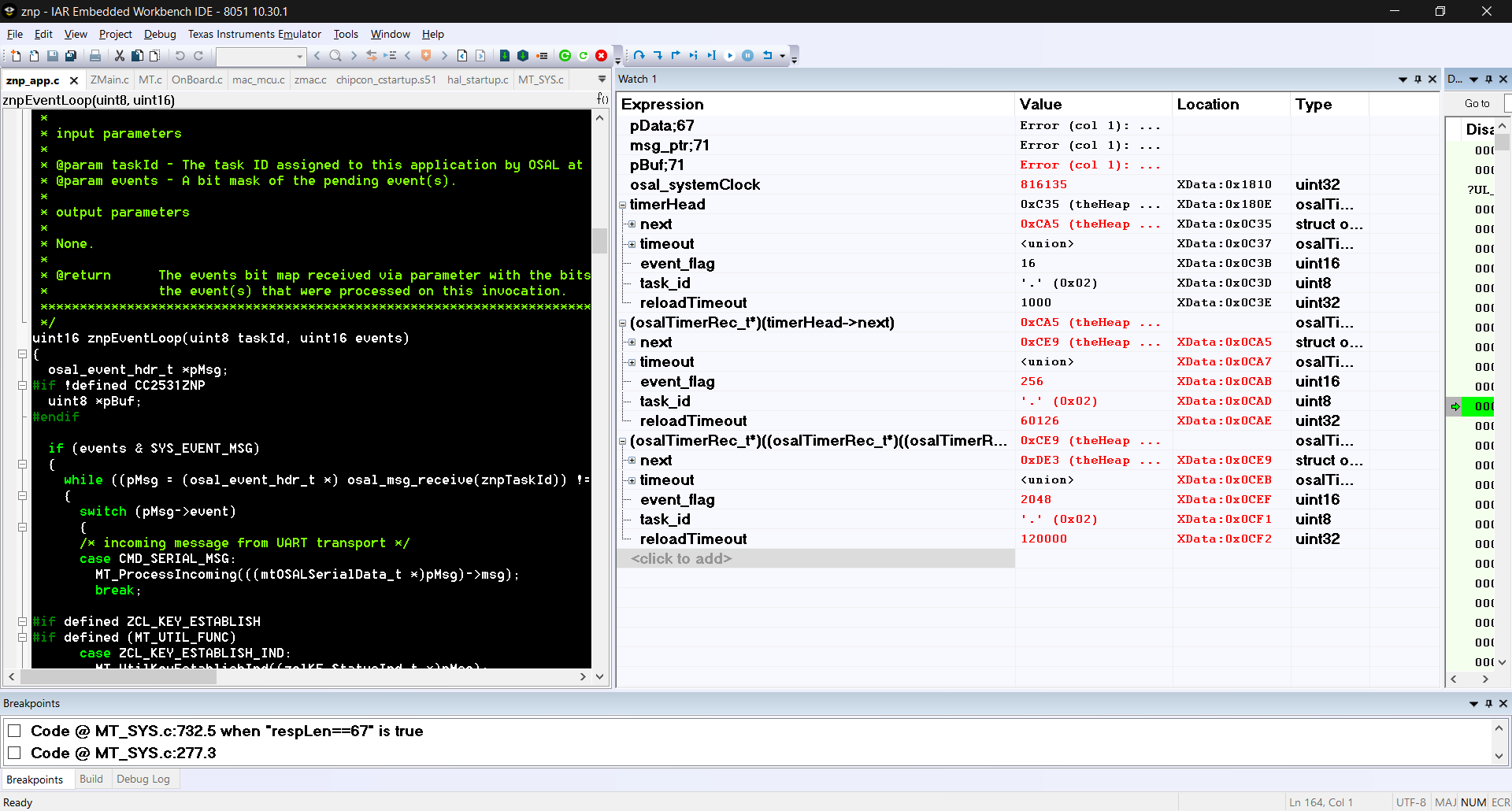
我对 TimerHead LinkedIn 列表的解释是它已损坏。 干净的链接列表在 EVENT_FLAGS 中只有一位。
屏幕截图应有助于理解这一点。 我还使用 Debug > Memory > Save 保存了内存。 我不知道重新加载它需要什么。

我加入日志。 ZNP 的最后一次通信如下所示:
[2020-11-22 17:11:58.996636]>[AF/AREQ]** DATA_CONFIRST** ZSuccessess EP:01:6 (SYS:4/TYPE:40/CMD:80)(8): :19603 44 80 00 01 06 c0 [2020-11-22 17:11:58.987306] 18 0x0000 SEQ→:Zfe CL7:Zfe 属性:Zfe 3:Zfe Cl 0x51 6 [2020-11-22 17:11:58.993800] 19621→IEEE 802.15.4 5 Ack ****不确定这是来自 ZNP 的有效通信,但仅在以下情况下: [2020-11-22 17:12:04.972770] 19638→0xec5c IEEE 802.15.4 52保留,dst: 0xec5c,BAD FCS
将来、我将类型转换为"next "、这样我就不需要将其转换到调试器中。
typedef struct osalTimerRec_s { struct osalTimerRec_s * next; osalTime_t timeout; uint16 event_FLAG; uint8 task_id; uint32 reloadTimeout; } osalTimerRec_t;
这是一个正常的链接列表:
我还通过更改 MT.c 中一个大变量的存储类来节省了一点 RAM:
之前: 239 887字节代码存储器 32字节数据存储器(+ 70绝对值) 7935字节 XDATA 存储器 192字节 iDATA 存储器 8位存储器 426字节常量存储器
之后:
239 887字节代码存储器 32字节数据存储器(+ 70绝对值) 7 891字节 XDATA 存储器 192字节 iDATA 存储 器8位存储 器470字节 const 存储器
这是串行日志和网关日志以及监听器日志。 希望这些设置能够识别导致此问题的原因 、我可以向项目发送下载链接(包括日志等)-由于它包含源代码、我可以通过专用网格来执行此操作。

