

Part Number: TMS320F280039C
编译器版本:TI v22.6.0.LTS
我需要对大数组或结构体进行清零,之前的方案是直接采用memset函数清零,例如:
memset((void *)&test1,0,sizeof(test1));
但发现编译器在256字以内时会采用RPT指令以生成效率更高的汇编代码,而在256字以上时则直接调用memset库函数,例如我定义了三个测试用的float数组,大小分别为127、128和129,并对其清零:
volatile float test1[127]; volatile float test2[128]; volatile float test3[129]; memset((void *)&test1,0,sizeof(test1)); //line 209 memset((void *)&test2,0,sizeof(test2)); //line 210 memset((void *)&test3,0,sizeof(test3)); //line 211
生成的汇编代码分别为:
.dwpsn file "../main.c",line 209,column 5,is_stmt,isa 0
MOVL XAR4,#||test1|| ; [CPU_ARAU] |209|
RPT #253
|| MOV *XAR4++,#0 ; [CPU_ALU] |209|
.dwpsn file "../main.c",line 210,column 5,is_stmt,isa 0
MOVL XAR4,#||test2|| ; [CPU_ARAU] |210|
RPT #255
|| MOV *XAR4++,#0 ; [CPU_ALU] |210|
.dwpsn file "../main.c",line 211,column 5,is_stmt,isa 0
MOV ACC,#258 ; [CPU_ALU] |211|
MOVB XAR5,#0 ; [CPU_ALU] |211|
MOVL XAR4,#||test3|| ; [CPU_ARAU] |211|
$C$DW$325 .dwtag DW_TAG_TI_branch
.dwattr $C$DW$325, DW_AT_low_pc(0x00)
.dwattr $C$DW$325, DW_AT_name("memset")
.dwattr $C$DW$325, DW_AT_TI_call
LCR #||memset|| ; [CPU_ALU] |211|
; call occurs [#||memset||] ; [] |211|
可以观察到test1和test2的清零均采用了RPT指令,用时分别为257和259个时钟周期,平均每字节约为1个时钟周期;而test3的清零则调用了memset库函数,用时4914个时钟周期,平均每字节花费19个时钟周期。库文件的c代码和汇编代码如下:
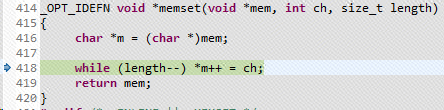

即便我打开level2的编译器优化,编译器对memset的处理依旧不变。所以有没有其他更好的办法256字以上数组或结构体进行清零呢?

