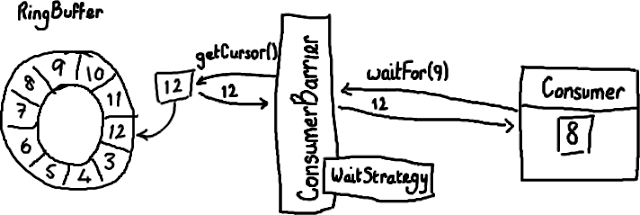
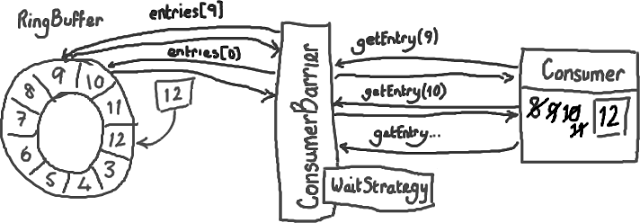
首先 - Ring Buffer。我对 Disruptor 的最初印象只有 Ring Buffer。后来我渐渐明白 Ring Buffer 结构是这个模式的中心,关键之处是 Disruptor 如何控制对它的访问。
Ring Buffer 究竟是什么?
正如名字描述那样 - 它是一个环 (圆形,首尾相接的),你可以把它当作一个缓存 (buffer),用来在一个线程上下文与另一个线程上下文之间传递数据。
(好吧,我是用 Paint 画的。我尝试画草图,希望强迫症没有掺和进来要求我画出完美的圆和直线)。
所以基本上 Ring Buffer 就是拥有一个序号指向下一个可用元素的数组。
如果你持续向 buffer 中写入数据(应该也会从里面读数据),这个序号会一直增长,直到绕过整个环。
要找到数组中当前序号指向的元素,你可以用 mod 运算。
sequence mod array length = array index
因此对于上面的 Ring Buffer,这个算法就是(用 JAVA 的 mod 语法):12 % 10 = 2。很简单。
其实图片里画着 10 个元素完全是一个意外。2 的 N 次方个元素会更好,因为计算机是用二进制思考的。
接下来呢?
如果你从 Wikipedia 查到 Circular Buffers,你会看到它与我们的实现方式有一个重要的差别-没有指向末尾的指针。我们只有下一个可用的序号。这是刻意的-选择 Ring Buffer 的根本原因是需要支持可靠的消息通信。我们需要把服务发出的消息存储起来,那么当另一个服务发来一个 NAK (拒绝应答信号) 说他们没有收到消息的时候,我们可以重新发送给他们。
Ring Buffer 看起来很理想。它用序号来指出 buffer 的末尾在哪里,而且当它收到一个 NAK 信号的时候,可以重发从那一点到当前序号之间的所有消息:
我们所实现的 Ring Buffer 与传统队列的区别是:buffer 里的对象不会被销毁-它们留在那儿直到下次被覆盖写入。这是与 Wikipedia 上的版本相比我们的实现不需要尾指针的原因。在我们的实现中,确定 Ring Buffer 是否重叠的工作,是由数据结构之外来完成的(这是生产者与消费者行为的一部分-如果你来不及等我写博客说明它,可以自己检出 Disruptor 代码)。
Ring Buffer 这么棒是因为...?
我们使用 Ring Buffer 这种数据结构,是因为它给我们提供了可靠的消息传递特性。这个理由就足够了,不过它还有一些其他的优点。
首先,Ring Buffer 比链表要快,因为它是数组,而且有一个容易预测的访问模式。这很不错,对 CPU 高速缓存友好 (CPU-cache-friendly)-数据可以在硬件层面预加载到高速缓存,因此 CPU 不需要经常回到主内存 RAM 里去寻找 Ring Buffer 的下一条数据。
第二点,Ring Buffer 是一个数组,你可以预先分配内存,并保持数组元素永远有效。这意味着内存垃圾收集(GC)在这种情况下几乎什么也不用做。此外,也不像链表那样每增加一条数据都要创建对象-当这些数据从链表里删除时,这些对象都要被清理掉。
文章缺少的部分
我没有提到如何避免环重叠,以及怎么向 Ring Buffer 读、写数据的细节。你也会注意到我在拿它和链表那样的数据结构相比较,我想没人会认为链表是实际问题的解决方案。
有趣的部分来自于拿 Disruptor 和队列之类的实现相比较。队列通常关注于维护队列的头和尾,添加和消费消息一类的东西。所有这些东西我还没有在 Ring Buffer 一节真正提到。这是因为 Ring Buffer 本身并不负责这些事情,我们把这些问题挪到了数据结构的外部。
-------————————————————————————————————————————————————————————————————
你也可以把你的理解和相关代码跟帖发来,大家一起学习










 个数据。如果读写指针指向同一位置,则缓冲区为空。如果写指针位于读指针的相邻后一个位置,则缓冲区为满。这种策略的优点是简单、鲁棒;缺点是语义上实际可存数据量与缓冲区容量不一致,测试缓冲区是否满需要做取余数计算。
个数据。如果读写指针指向同一位置,则缓冲区为空。如果写指针位于读指针的相邻后一个位置,则缓冲区为满。这种策略的优点是简单、鲁棒;缺点是语义上实际可存数据量与缓冲区容量不一致,测试缓冲区是否满需要做取余数计算。