

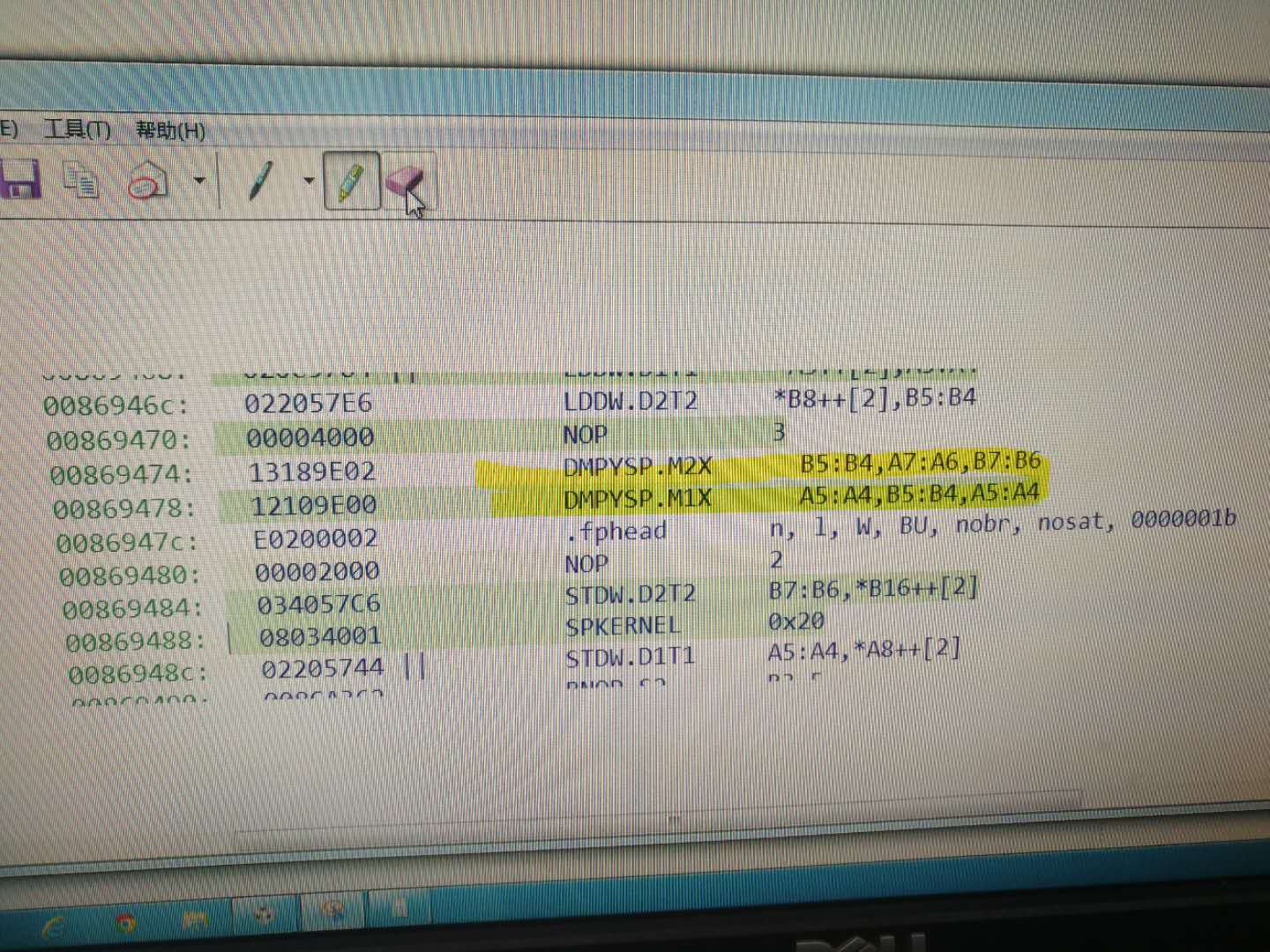
从芯片的数据手册得知,对于单精度数据,.M可以在一个时钟周期中完成4次乘法。那么可以认为,6678的单核对单精度数据的乘法执行效率为,一个时钟周期完成8次乘法。但目前测试向量点乘函数,发现长度为4096的向量,点乘的耗时为3496cycles,这如何解释?如何使得,芯片中.m使用率最高,也就是说一个时钟周期可完成8次单精度数据乘法
从芯片的数据手册得知,对于单精度数据,.M可以在一个时钟周期中完成4次乘法。那么可以认为,6678的单核对单精度数据的乘法执行效率为,一个时钟周期完成8次乘法。但目前测试向量点乘函数,发现长度为4096的向量,点乘的耗时为3496cycles,这如何解释?如何使得,芯片中.m使用率最高,也就是说一个时钟周期可完成8次单精度数据乘法


{kind=link}