Part Number: TMS320C6657
EMIF16配置为SS模式,共开启两个片选信号CE0和CE1,CE0写一个16bit周期大约为208ns

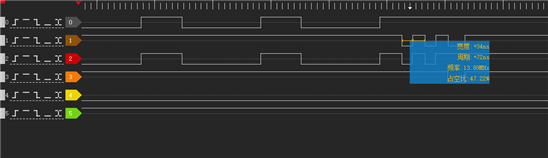
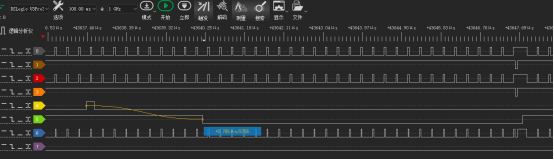
上图为出现延迟问题:
配置:
波形0:CE0
波形1:CE1
波形2:WE
波形3: OE
波形4: 外部输入IO信号
波形5:外部输入中断函数
在主函数内不断地往CE0进行写入数据,每次写入都为16bit,当外部输入IO信号触发高电平时进入中断处理函数,中断处理函数(优先级为0x16)先写入CE1两个16bit数据,再读取CE1一个16bit数据。
问题描述:
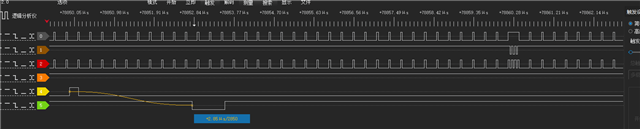
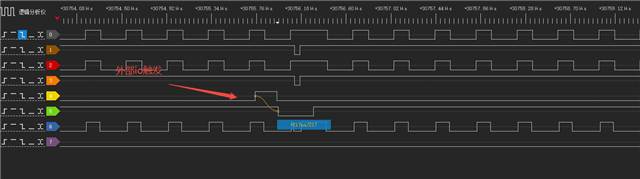
1.中断处理函数触发发生了延迟,大概为12个emif16 CE0写周期,该延迟正在处理CE0的数据下发。
2.写CE1时,即片选从CE0切换到CE1时也发生了延迟,大概为26个emif16 CE0写周期,该延迟正在处理CE0的数据下发。

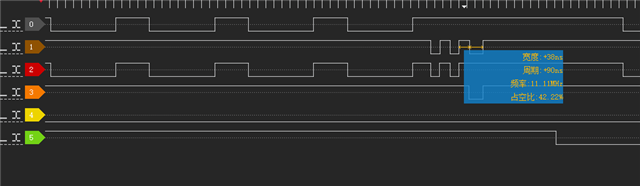
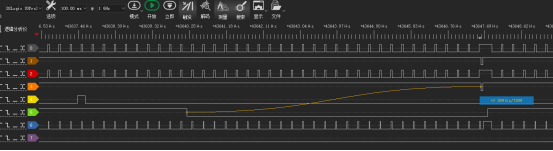
上图操作为:
在书函数内不断地从CE0读取数据,每次读取都为16bit,当外部输入IO信号触发高电平时进入中断处理函数,中断处理函数(优先级为0x16)先写入CE1两个16bit数据,再读取CE1一个16bit数据。
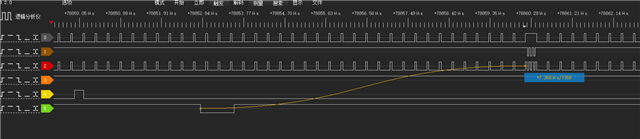
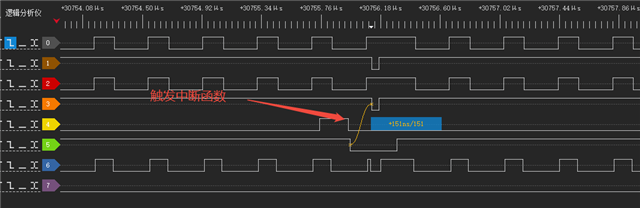
读的时候中断处理函数触发时间为872ns,较为合理,并且片选切换时也不存在较大的延迟处理CE0的数据。
期望:
不希望出现图1的情况,导致中断处理函数以及片选切换时,仍在等待未处理完的CE0数据,因为该中断需要处理实时数据,请问有什么解决办法?