请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM243X - MCU-PLUS-SDK主题中讨论的其他器件:AM2432
工具/软件:
您好:
我正在使用[enet_layer2_icssg]、我针对 EtherCAT 通信实验进行了修改。
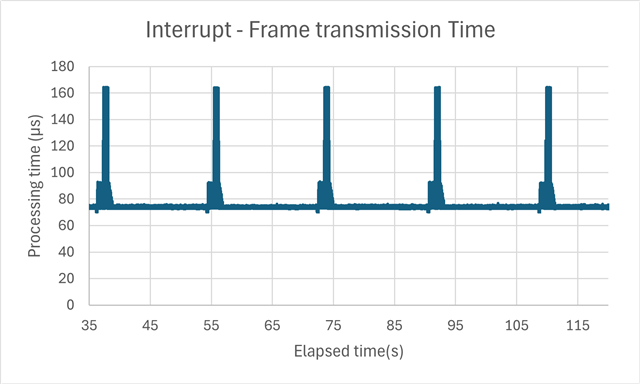
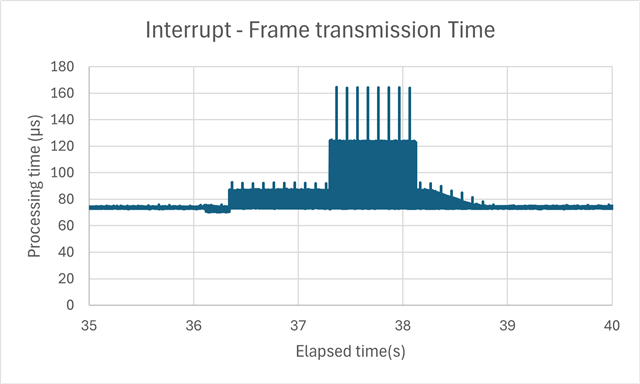
Tx 任务在每个 500μs 都会以中断运行、每次定期向从器件发送一个大约 1300字节 的帧。
发送和接收帧没有问题、但我发现大约每 16 秒会发生大约 2s 的延迟。
测量是使用来自 500μs 中断的 ECAP 模块完成的、以测量帧实际从 PHY 发送的时间。
~、尽管通常需要发送大约 70μs、但大约每 16 秒会发生 90 μ s 120μs 延迟。
出于调试目的、我停止使用“EnetDma_submitTxPktQ (perCtxtx->hTxCh[0]、&txSubmitQ);“、并将发送任务设置为仅创建帧而不发送帧、因此自然没有延迟。
因此、我认为如果继续使用 EnetDma_submitTxPktQ、将执行一些过程、例如内存刷新、
消耗 CPU 资源并导致高负载。
这种延迟的原因是什么?
sdk mcu_plus_sdk_am243x_11_00_00_15
使用的电路板 AM243xEVM/定制电路板 (AM2432)
电路板有一个 ICSSG 端口连接到从器件、另一个端口断开
代码(部分省略)
// tx EtherFrame
EnetQueue_initQ(&txSubmitQ);
/* Retrieve TX packets from driver and recycle them */
EnetMp_retrieveFreeTxPkts(perCtxt);
/* Dequeue one free TX Eth packet */
txPktInfo = (EnetDma_Pkt *)EnetQueue_deq(&gEnetMp.txFreePktInfoQ);
if (txPktInfo != NULL)
{
/* Fill the TX Eth frame with test content */
txFrame = (EthFrame *)txPktInfo->sgList.list[0].bufPtr;
// EtherNet hdr setting
pre_fill_ecat_frame(txFrame);
// EtherCat data setting
fill_ecat_frame(txFrame);
txPktInfo->sgList.list[0].segmentFilledLen = 1300;
txLen = txPktInfo->sgList.list[0].segmentFilledLen;
txPktInfo->sgList.numScatterSegments = 1;
txPktInfo->chkSumInfo = 0U;
txPktInfo->appPriv = &gEnetMp;
EnetDma_checkPktState(&txPktInfo->pktState , ENET_PKTSTATE_MODULE_APP , ENET_PKTSTATE_APP_WITH_FREEQ , ENET_PKTSTATE_APP_WITH_DRIVER);
/* Enqueue the packet for later transmission */
EnetQueue_enq(&txSubmitQ, &txPktInfo->node);
status = EnetDma_submitTxPktQ(perCtxt->hTxCh[0], &txSubmitQ);